Iniciamos uma série de artigos relacionados ao tema Engenharia de Detecção com o objetivo de contribuir para a comunidade de cibersegurança, aprofundando temas que impactam diretamente o dia a dia dos times que atuam com SIEM, seja para criação de regras, concepção de cenários de ameaça ou gestão de casos de uso.
No primeiro artigo [1], explicamos o que é o SIGMA e como podemos utilizar esse padrão na construção de casos de uso. Dando continuidade, neste post iremos falar sobre um tema muito importante: Falso Positivos relacionados a detecção de ameaças e como isso afeta o dia a dia de uma operação de segurança.
Contextualização
Antes de falarmos sobre Falso Positivos, precisamos entender o que são casos de uso. Conforme explicado no primeiro artigo [1], um caso de uso tem o objetivo de detectar um cenário de ameaça por meio do mapeamento de padrões maliciosos presentes em logs, comunicações de rede etc. Por fim, esta detecção poderá ser implementada em uma solução de segurança, como por exemplo o SIEM (Security Information and Event Management) que fará o correlacionamento destas informações gerando alertas.
Outro ponto importante de entendermos é que a matéria prima utilizada na construção de uma lógica de detecção, são os dados (telemetria) gerados pelos ativos¹ e coletados pelos sensores², conforme imagem abaixo:
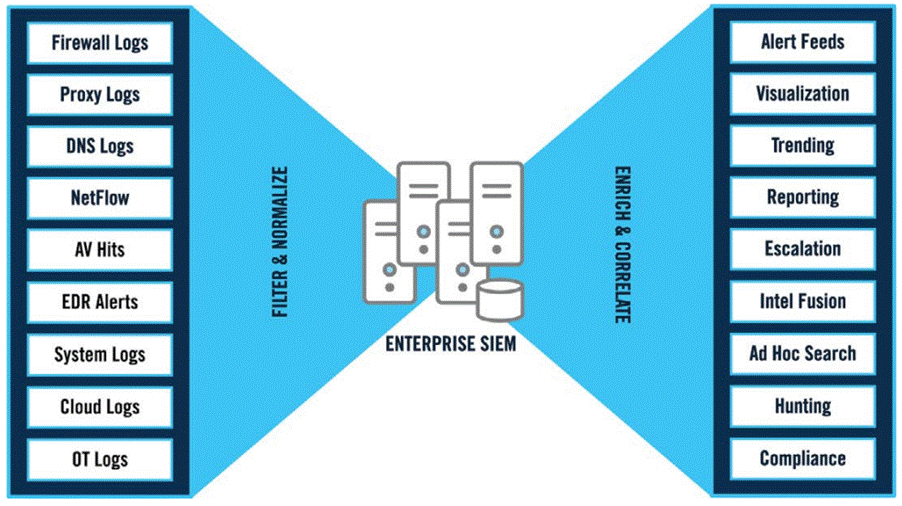
¹ Ativos: qualquer dispositivo tecnológico utilizado pelas empresas para processar, armazenar e transferir dados.
² Sensores: tecnologia capaz de capturar dados dos ativos, ex.: antivírus, EDR, coletor de logs, etc.
No começo desse processo, durante a fase de aquisição dos dados, a volumetria gerada irá variar de acordo com o tamanho do ambiente que está sendo monitorado, porém, podemos facilmente chegar a milhões de eventos por dia ou até mesmo por hora. Então, estes eventos serão filtrados, armazenados e correlacionados no SIEM. Nesse momento, com base nas lógicas de detecção implementadas no SIEM, o número de alertas gerados para o analista do SOC tratar deverá ser mínimo, conforme imagem abaixo:
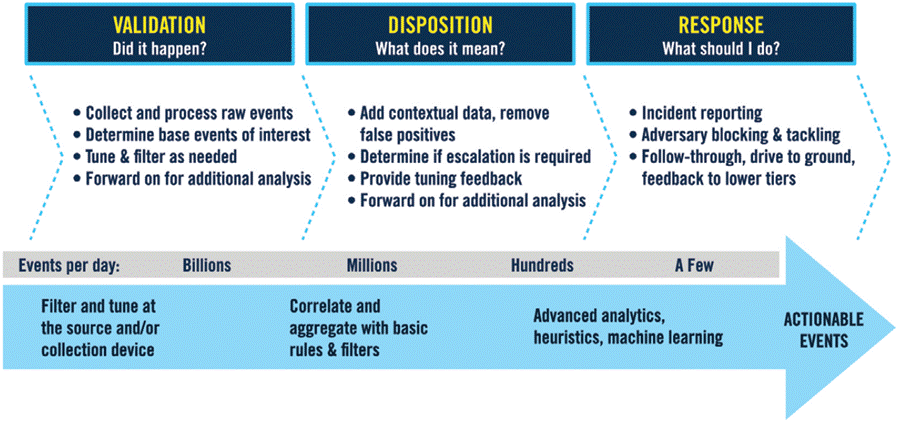
Sendo assim, caso as lógicas não tenham sido bem desenvolvidas e produzam um grande volume de alertas considerados como “falso positivos”, os analistas irão gastar muito tempo para analisar e responder estes alertas, deixando muitas vezes de priorizar um alerta “verdadeiro positivo” podendo agravar o risco desta ameaça.
O que são Falso Positivos?
Quando pensamos em detectar anomalias, basicamente analisamos o comportamento de um grupo de elementos e comparamos com outro grupo de elementos para identificarmos as diferenças (anomalias) ou desvios do padrão avaliado. Durante o processo de classificação binária [3], onde elementos são classificados em dois grupos com base em uma ou várias regras de classificação, podem haver erros gerando falso positivos e falso negativos.
Falso positivo, em um conceito geral, quer dizer que algo aparenta ser verídico, mas, na verdade, não é. Este conceito é utilizado em diferentes áreas do conhecimento, como por exemplo na área da saúde, onde um paciente pode realizar um exame e ter um diagnóstico falso positivo, podendo acarretar em diversos problemas caso seja realizado um tratamento para algo que ele não tenha.
Falso negativo, é justamente o contrário, quando algo deveria ser detectado, mas não é. Temos um exemplo recente na área da saúde relacionado a detecção do vírus covid-19 em seres humanos. Em março de 2020, foi aprovado a utilização de testes para detecção do vírus, sendo que uma das principais preocupações era a taxa de falso negativo, pois a pessoa que não fosse diagnosticada com o vírus, não seguiria as recomendações de isolamento e o vírus poderia se espalhar para mais pessoas.
No contexto de detecção de ameaças em dispositivos cibernéticos, temos as seguintes definições:
NIST
Falso Positivo: um alerta que indica incorretamente que uma atividade maliciosa está ocorrendo. [4]
Falso Negativo: classificação incorreta de uma atividade maliciosa como benigna. [5]
MITRE
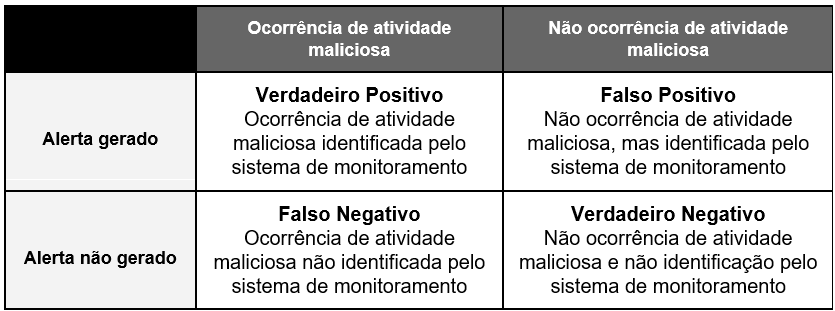
O principal desafio de um sistema de detecção é ter uma taxa de verdadeiro positivo alta e a menor taxa possível de falso negativo, porém, isso pode acabar levando a ferramenta ter mais falso positivo. Muitos alertas falso positivos obrigam os analistas a gastarem mais tempo analisando estes eventos e com o passar do tempo, o sistema de detecção pode acabar perdendo a credibilidade entre os analistas, levando-os a ignorar os seus alertas. Dessa forma, um alerta verdadeiro positivo também poderia ser ignorado.
Uma possibilidade de identificar falsos negativos em seu sistema de monitoramento, é a realização de um processo chamado adversary simulation, onde o Red Team especializado na execução de testes de penetração, poderá simular a presença de um adversário no ambiente. Assim, as detecções implementadas poderão ser testadas e aprimoradas, sem a necessidade da ocorrência de um incidente.
Lidando com Falso Positivos
Entendendo o conceito de falso positivo, chegamos à conclusão que eles estarão presentes no dia a dia da operação de segurança e isso não é necessariamente um problema. No mundo perfeito, nós desejamos coletar os dados de todos os ativos da empresa, porém isso trará um maior volume de alertas e consequentemente um número maior de falso positivo. Já na realidade, nós precisamos selecionar ativos e fontes de dados conhecidos como “as joias da coroa” do nosso negócio, que basicamente são os ativos mais importantes para o funcionamento do negócio. Dessa forma e, com um constante gerenciamento das ferramentas, conseguimos achar o “ponto perfeito” no quesito volume de alertas.
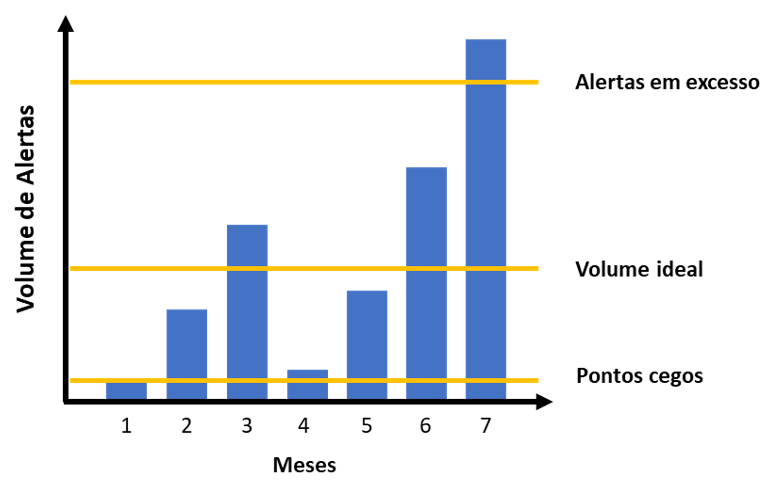
No processo de monitoramento e detecção de ameaças [6], temos 2 extremos:
- Alertas demais que deixarão os analistas sobrecarregados e por muita das vezes deixando de olhar para o que de fato está trazendo risco para o negócio;
- Alertas de menos (nem mesmo os falsos positivos) que pode indicar que o ambiente não está sendo monitorado da forma correta, pois podemos estar cegos em alguns pontos. Exemplos de pontos cegos:
- Falta de fontes de dados, ou seja, os logs necessários não estão sendo coletados;
- Ferramentas mal configuradas e que não geram logs úteis para serem monitorados;
- Má gestão das listas de exceção, ou seja, existe uma lista muito permissiva que acaba classificando diversas situações como exceção.
O volume ideal irá depender de alguns fatores como: quantidade de ativos monitorados, quantidade de ferramentas de segurança disponíveis, quantidade de fontes de dados sendo monitoradas, entre outros. Precisamos entender que parte dos alertas gerados poderão ser falso positivos e dessa forma, devemos aprender com eles e gerenciá-los de modo que não afetem a investigação dos demais.
Quando olhamos para este assunto sob a ótica de engenharia de detecção, podemos ter um conflito entre as oportunidades de detecção identificadas e os falsos positivos mapeados, pois muitas vezes o comportamento identificado como malicioso, condiz com o comportamento de um administrador do sistema. Exemplo: o MITRE ATT&CK possui a técnica T1087.002 – Account Discovery: Domain Account [7] que diz respeito ao procedimento de listar contas e grupos de um domínio. Esta técnica pode ser utilizada por atacantes para descobrir informações do ambiente e progredir nas próximas etapas do seu ataque, porém, este procedimento também pode ser utilizado por um administrador que precisa consultar informações de um determinado usuário no AD (Active Directory). Neste cenário, como podemos diferenciar o comportamento malicioso do comportamento benigno?
Uma possibilidade seria, imaginando que o atacante não conhece as contas dos usuários deste ambiente, que ele executará este comando diversas vezes para coletar o máximo de informações possíveis, talvez até automatizando essa tarefa através de um script. Dessa forma, conseguimos criar uma detecção observando a volumetria de processos criados que tenha na commandline argumentos específicos considerando um determinado período de tempo, como por exemplo: 30 comandos executados em 5 segundos. Assim, conseguiremos identificar um cenário de ameaça onde o atacante está realizando a descoberta dos usuários através de uma ferramenta automatizada.
Sendo assim, podemos definir uma oportunidade de detecção como: uma ou a combinação de algumas evidências coletadas de um dispositivo que indique um possível comprometimento e, sempre que der, não gere falso positivo.
Outro ponto importante é o gerenciamento constante das ferramentas de segurança, pois elas terão falso positivos naturalmente e para isso precisamos desenvolver processos que auxiliem no gerenciamento destes alertas. Exemplos:
Antivírus
Uma ferramenta de antivírus pode trabalhar de diferentes formas, seja utilizando uma base de assinaturas, heurística, observando comportamento ou até mesmo machine learning para detectar padrões maliciosos, o fabricante da solução é responsável por gerenciar e alimentar essa base de conhecimento para detectar novas ameaças.
Hoje em dia, as empresas precisam desenvolver aplicações para suportar seus processos de negócio e estas, podem executar procedimentos nos ativos que sejam iguais a de um malware, como por exemplo, criar novos processos ou executar comandos para cópia de arquivos. A ferramenta de antivírus não saberá que se trata de uma aplicação legítima e irá gerar um alerta.
A solução deste problema é mapear os alertas gerados pela ferramenta e entender o comportamento padrão e esperado da aplicação. Após isso, regras de exceção poderão ser criadas para que novos alertas não sejam gerados.
WAF (Web Application Firewall)
A ferramenta WAF também trabalha com base em assinaturas disponibilizadas pelos fabricantes do equipamento. Inclusive, muitas dessas ferramentas possuem um modo de aprendizado que tem o objetivo de entender e aprender o comportamento das aplicações, ficando mais fácil diferenciar um comportamento padrão de um malicioso. Outra prática comum é a criação de políticas específicas para cada aplicação, onde são acrescentadas exceções para comportamentos esperados e que a ferramenta identificou como algo malicioso.
IDS (Intrusion Detection System) e IPS (Intrusion Prevention System)
Assim como as outras ferramentas, estas também trabalham com base em assinaturas, só que com o objetivo de identificar tráfego malicioso na rede. O IDS apenas detecta padrões maliciosos, já o IPS pode detectar e bloquear estas comunicações, sendo muito comum a criação de políticas por ambientes e exceções para comunicações de rede que geram alertas falso positivo.
Scanner de Vulnerabilidade
Esta ferramenta tem o objetivo de identificar vulnerabilidades nos ativos da empresa. Existem diversos métodos para validar se um equipamento está vulnerável, como por exemplo, checar a versão do pacote instalado, comparando-a com a base de conhecimento da ferramenta. Outra possibilidade, é a execução de procedimentos no equipamento esperando uma resposta específica e caso demore mais do que o normal, isso poderá indicar que o equipamento está vulnerável. Exemplo: Time-based Blind SQL Injection [8].
Outros fatores que podem levar a um falso positivo durante o scan de vulnerabilidade, é a falta de permissionamento adequado, onde a ferramenta tem acesso a informações parciais, falhas de autenticação (quando não utilizado agentes) e rotinas que não são executadas pois não houve comunicação com a máquina alvo.
Todas as ferramentas mencionadas acima, podem gerar falso positivos se não forem bem gerenciadas. Conforme vimos anteriormente, é a partir dessas informações que conseguimos construir as lógicas de detecção implementadas no SIEM.
Gerenciando Falso Positivos
Um bom processo de monitoramento e detecção de ameaças, precisa conter acompanhamentos através de métricas (KPIs) dos falsos positivos e até mesmo um fluxo de tratativa destes alertas, mas antes precisamos entender como podem surgir falso positivos neste processo. Abaixo está listado 4 cenários de falso positivo que podem ocorrer:
1 – Cenário de Ameaça
Problema: Estudando os TTPs (Táticas, Técnicas e Procedimentos) do MITRE ATT&CK, conseguimos imaginar diversos cenários de ameaça. Neste exemplo, vamos focar na técnica T1110 – Brute Force e imaginar que chegou diversos alertas de falhas de autenticação no servidor de aplicação web. Automaticamente, já relacionamos esse comportamento a um possível brute force, porém, analisando o evento descobrimos que o IP de origem pertence a ferramenta de scan de vulnerabilidades. Outro exemplo seria um alerta relacionado a técnica T1030 – Data Transfer Size Limits que normalmente está associado a um procedimento de exfiltração de informações, porém, também pode ser um comportamento muito semelhante de uma solução de backup.
Solução: Criar exceções de acordo com o mapeamento de comportamentos padrão do ambiente que está sendo monitorado. Caso o volume de falso positivo seja alto, a regra de detecção pode ser desativada até que os ajustes sejam feitos.
2 – Lógica de Detecção
Problema: As lógicas de detecção servem como base para a implementação da regra de detecção no SIEM. Durante a concepção da lógica, muita das vezes, não temos acesso ao procedimento completo realizado pelo atacante ou ao artefato malicioso utilizado durante o ataque. Por conta disso, podemos mapear um padrão que não necessariamente é malicioso. Outro problema seria a lógica ter um objetivo, mas na realidade está gerando alertas para outras situações.
Solução: Necessário ajustar a lógica de detecção com base no cenário de ameaça e procedimento analisado.
3 – Regra de Detecção
Problema: As regras de detecção que são implementadas no SIEM, podem derivar de uma lógica de detecção, a depender da estratégia e estrutura organizacional da empresa. Portanto, caso não seja entendido o objetivo, data source utilizado e demais informações da lógica, existe o risco de a regra ser implementada de maneira errada. Pode haver também, customizações na hora da implementação e isso poderá gerar falso positivos caso não seja feita uma análise prévia.
Solução: Necessário ajustar a regra de acordo com a lógica desenvolvida.
4 – Passthrough (ferramentas de segurança)
Problema: Como vimos anteriormente, as ferramentas de segurança são ótimas fontes de dados para sabermos se alguma atividade maliciosa está ocorrendo no ambiente, porém, acreditar fielmente no alerta gerado pela ferramenta pode ser um erro.
Solução: Neste caso, recomenda-se rever as configurações da ferramenta de modo que não gere falso positivo. Talvez seja necessário a criação de regras de exceção ou o envolvimento do fabricante.
5 – Análise errada
Problema: No processo de gerenciamento de incidentes de segurança da informação, primeiramente devemos avaliar os eventos gerados, contextualizando-os e correlacionando-os com outras informações. Caso isso não ocorra, o analista poderá, de forma precipitada, indicar que o alerta gerado é um falso positivo.
Solução: Criar processos e adotar a utilização de playbooks e runbooks que auxiliará os analistas a responderem aos incidentes. A padronização das tratativas irá agilizar a resposta e diminuirá a ocorrência de erros na classificação dos alertas.
Cada cenário de falso positivo, poderá necessitar de atividades específicas exercidas por diferentes times. Para isso, ter implementado um fluxo de comunicação entre os times, ajudará os analistas na tomada de decisão durante o processo de triagem e classificação dos alertas. Abaixo está um exemplo de fluxo:
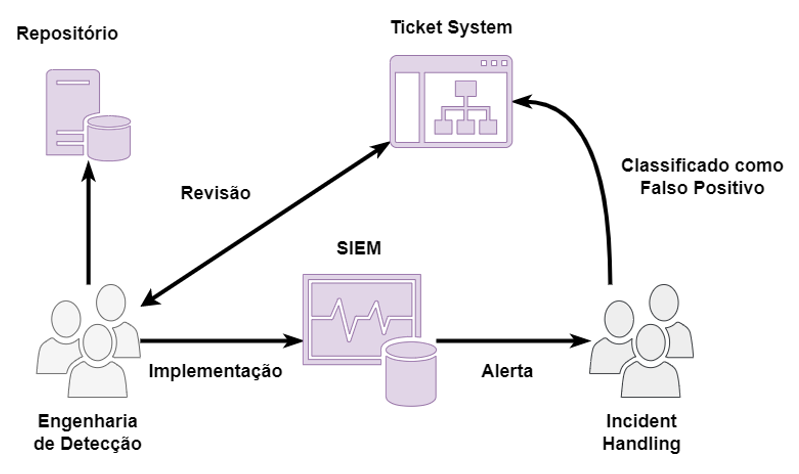
Quanto mais automatizado esse fluxo for, mais rápido os times envolvidos poderão corrigir o problema. Podemos citar o exemplo de alertas falso positivos atrelados a um IoC (Indicator of Comprise), caso seja utilizado uma ferramenta de gerenciamento de IoC como o MISP-broker [9], o analista de resposta a incidente poderá facilmente indicar através do sistema MISP que determinado IoC gerou um alerta falso positivo e o mesmo será removido do SIEM automaticamente. Também podemos estabelecer processos DevOps para a criação das regras de detecção, agilizando a correção e implementação da versão corrigida.
Outro item que deve ser estabelecido, é um KPI para acompanhar a taxa de falso positivos ocorridos ao longo do mês:

O resultado será expressado em %. Abaixo, podemos observar um exemplo de como interpretar esses dados:
- 0% – 5%: comportamento dentro do normal e esperado para uma volumetria média de 100.000 eventos por mês (exemplo);
- 5,1% – 15%: falso positivos devem ser avaliados para entendimento da causa raíz, onde processos e configurações devem ser ajustados;
- maior do que 15,1%: necessário realizar uma revisão sistemática dos processos e ferramentas envolvidas no processo de monitoramento e resposta a incidentes.
Conforme dito anteriormente, cada ambiente será composto de tecnologias e processos de monitoramento diferentes, portanto as porcentagens especificadas acima devem ser avaliadas para o contexto do seu processo.
Também podemos estabelecer outros indicadores para acompanharmos esses alertas, como por exemplo:
- Porcentagem de alertas FP por regra implementada: com este valor podemos identificar quais regras estão gerando mais falso positivos;
- Porcentagem de alertas FP por cenário: avaliar se o cenário de ameaça que está sendo monitorado faz sentido para o negócio;
- Total de horas gastas na análise dos FP: podemos identificar o custo gerado por horas dedicadas na tratativa de falso positivos;
- Número de alertas categorizados como FP mas que acabou gerando um incidente: faz parte do processo de melhoria contínua, onde devemos aprender com os erros operacionais cometidos.
Quando falamos em regras de SIEM, podemos documentar uma série de metadados que ajudarão os demais times do SOC a entender o objetivo e funcionamento da regra, como por exemplo:
- Falsos positivos mapeados: durante o processo de criação da regra, caso seja mapeado um falso positivo, este deve ser documentado para que o time de resposta à incidentes tenha ciência disso durante a avaliação do alerta;
- Tipo da regra: podemos ter regras com objetivos diferentes, ou seja, regras mais específicas que identifiquem um TTP e podem gerar um alerta, já regras mais abrangentes que podem gerar falso positivos, podem ser utilizadas para a realização de um hunting no ambiente. Essa diferenciação faz com que o SOC não deixe de mapear eventos maliciosos e separe entre alertas e demais análises que possam ser realizadas no ambiente;
- Volumetria: esta é uma informação difícil de ser avaliada, porém, caso seja possível identificar com base em eventos passados, podemos documentar a volumetria de alertas esperado para determinada regra. Exemplo: baixo, médio ou alto;
- Timeframe para análise: este artifício já é utilizado para definir alguns padrões maliciosos, como por exemplo 300 falhas de autenticação em 2 segundos, porém, caso observarmos que a volumetria de eventos é alta, mas mesmo assim faz sentido monitorarmos, podemos dizer ao SIEM que verifique os logs a cada x tempo, sendo x um valor em minutos ou horas;
- Visibilidade: também podemos dizer que o alerta gerado para esta regra não precisa ser encaminhado para um analista de resposta a incidentes tratar. Ao invés disso, poderá aparecer em um dashboard ou relatório para ser avaliado posteriormente. Normalmente utilizamos esta opção para alertas relacionados a regras de negócio.
Conclusão
Neste artigo, apresentamos os conceitos relacionados a falso positivo no contexto de detecção de ameaças cibernéticas, como podemos lidar com eles e, o principal, como podemos gerenciá-los sabendo que é algo esperado que ocorra no processo de monitoração e resposta a incidentes de segurança. Conforme explicado, precisamos estabelecer processos e indicadores para que os falso positivos sejam acompanhados e não gerem custos operacionais, seja na classificação errada do evento que pode se tornar um incidente crítico ou na operação de segurança sobrecarregada por conta de muitos alertas.
Referências
[1] Tempest Security Intelligence, “Desvendando o SIGMA (yaml) para engenharia de detecção”, 30 de setembro de 2021. Disponível em: https://sidechannel.blog/desvendando-o-sigma-yaml-para-engenharia-de-deteccao/
[2] The MITRE Corporation, “11 Strategies of a World-Class Cybersecurity Operations Center”, 31 de março de 2022. Disponível em: https://www.mitre.org/sites/default/files/ 2022-04/11-strategies-of-a-world-class-cybersecurity-operations-center.pdf
[3] Wikipedia, “Binary Classification”, 2 de novembro de 2022. Disponível em: https://en.wikipedia.org/wiki/Binary_classification
[4] NIST, “False Positive”, 03 de julho de 2019. Disponível em: https://csrc.nist.gov/glossary/term/false_positive
[5] NIST, “False Negative”, 03 de julho de 2019. Disponível em: https://csrc.nist.gov/glossary/term/false_negative
[6] SANS, “When Being Wrong is Right The Role of False Positives in Building a Detection Pipeline”, 21 de outubro de 2019. Disponível em: https://www.sans.org/presentations/when-being-wrong-is-right-the-role-of-false-positives-in-building-a-detection-pipeline/
[7] The MITRE Corporation, “T1087.002 – Account Discovery: Domain Account”, 25 de agosto de 2022. Disponível em: https://attack.mitre.org/techniques/T1087/002/
[8] OWASP, “Blind SQL Injection”, 5 de outubro de 2020. Disponível em: https://owasp.org/www-community/attacks/Blind_SQL_Injection
[9] Tempest, “Indicadores de Comprometimento na detecção de incidentes e redução de falso positivos na prática”, 5 de agosto de 2022. Disponível em: https://sidechannel.blog/indicadores-de-comprometimento-na-deteccao-de-incidentes-e-reducao-de-falsos-positivos-na-pratica/