We’ve started a series of articles on the topic of Detection Engineering with the aim of contributing to the cybersecurity community by exploring topics that have a direct impact on the daily lives of teams working with SIEM, whether it’s creating rules, designing threat scenarios or managing case studies.
In the first article [1], we explained what SIGMA is and how we can use this standard to build use cases. Moving on, in this post we’re going to talk about a very important topic: False Positives related to threat detection and how this affects the routine of a security operation.
Background
Before we talk about False Positives, we need to understand what case studies are. As explained in the first article [1], a case study aims to detect a threat scenario by mapping malicious patterns present in logs, network communications, etc. Finally, this detection can be implemented in a security solution, such as SIEM (Security Information and Event Management), which will correlate this information and generate alerts.
Another important point to remember is that the raw material used to build a detection logic is the data (telemetry) generated by the actives¹ and collected by the sensors², as shown in the image below:
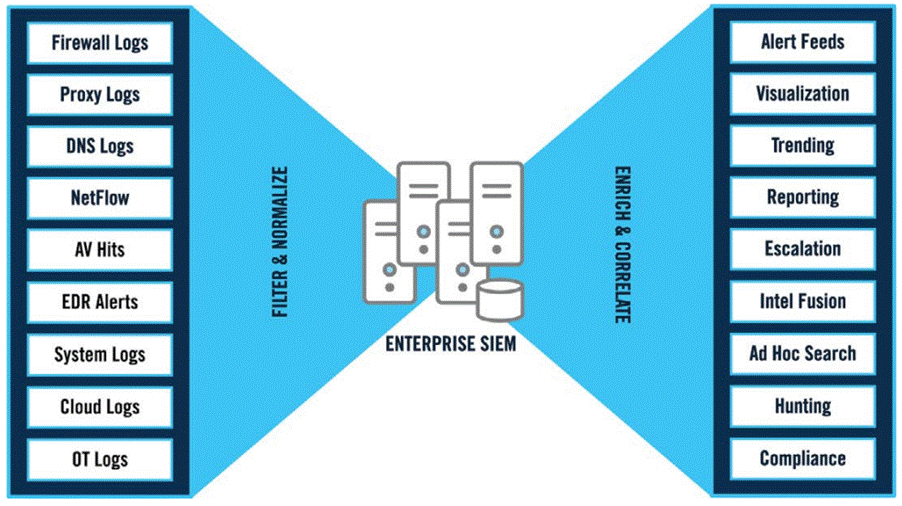
¹ Actives: any technological device used by companies to process, store and transfer data.
² Sensors: technology capable of capturing data from assets, e.g. antivirus, EDR, log collector, etc.
At the start of this process, during the data acquisition phase, the volume generated will vary according to the size of the environment being monitored, but we can easily reach millions of events per day or even per hour. These events will then be filtered, stored and correlated in the SIEM. At this point, based on the detection logic implemented in the SIEM, the number of alerts generated for the SOC analyst to deal with should be minimal, as shown in the image below:
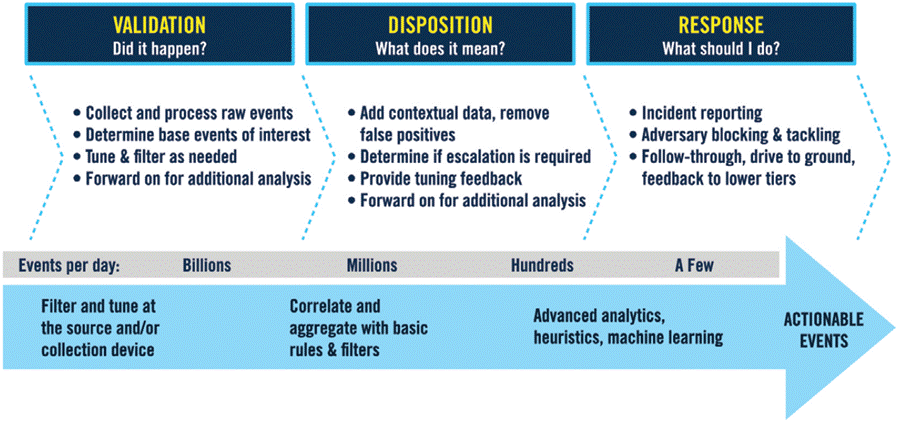
Image 2 – SIEM lifecycle. Source: MITRE [2]
Therefore, if the logics have not been well developed and produce a large volume of alerts considered to be “false positives”, analysts will spend a lot of time analyzing and responding to these alerts, often failing to prioritize a “true positive” alert and potentially aggravating the risk of this threat.
What are False Positives?
When we think about detecting anomalies, we basically analyze the behavior of a group of elements and compare it with another group of elements to identify differences (anomalies) or deviations from the evaluated pattern. During the binary classification process [3], where elements are classified into two groups based on one or more classification rules, there can be errors generating false positives and false negatives.
False positive, in a general concept, means that something appears to be true, but in fact it’s not. This concept is used in different areas of knowledge, such as healthcare, where a patient can undergo a test and have a false positive diagnosis, which can lead to many problems if a treatment is performed for something they don’t have.
False negative is the exact opposite, when something should be detected but isn’t. We have a recent example in the health area related to the detection of the covid-19 virus in humans. In March 2020, the use of tests to detect the virus was approved, and one of the main concerns was the false negative rate, since the person who wasn’t diagnosed with the virus wouldn’t follow the isolation recommendations and the virus could spread to more people.
In the context of detecting threats in cyber devices, we have the following definitions:
NIST
False Positive: an alert that incorrectly indicates that malicious activity is occurring.[4]
False Negative: incorrect classification of a malicious activity as benign.[5]
MITRE
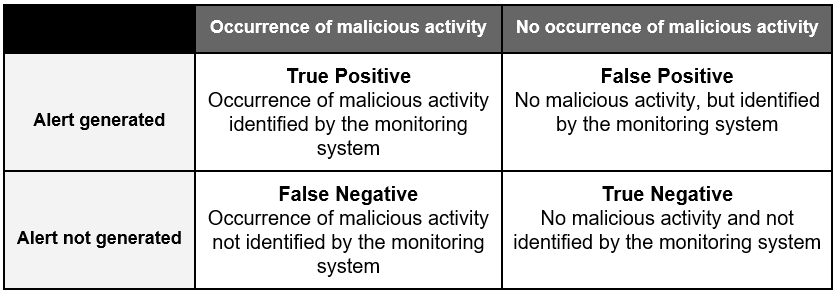
The main challenge for a detection system is to have a high true positive rate and the lowest possible false negative rate, but this can lead to the tool having more false positives. Too many false positive alerts force analysts to spend more time analyzing these events and over time, the detection system can end up losing credibility among analysts, leading them to ignore its alerts. As a result, a true positive alert could also be ignored.
One way of identifying false negatives in your monitoring system is to carry out a process called adversary simulation, where the Red Team, which specializes in running penetration tests, can simulate the presence of an adversary in the environment. This allows the detections implemented to be tested and improved, without the need for an incident to occur.
Dealing with False Positives
Understanding the concept of false positives, we conclude that they will be present in the routine of security operations and that this isn’t necessarily a problem. In a perfect world, we’d want to collect data from all the company’s actives, but this would result in a higher volume of alerts and consequently a higher number of false positives. In reality, however, we need to select assets and data sources known as the “crown jewels” of our business, which are basically the most important actives for the operation of the business. This way, and with constant management of the tools, we manage to find the “perfect point” in terms of the volume of alerts.
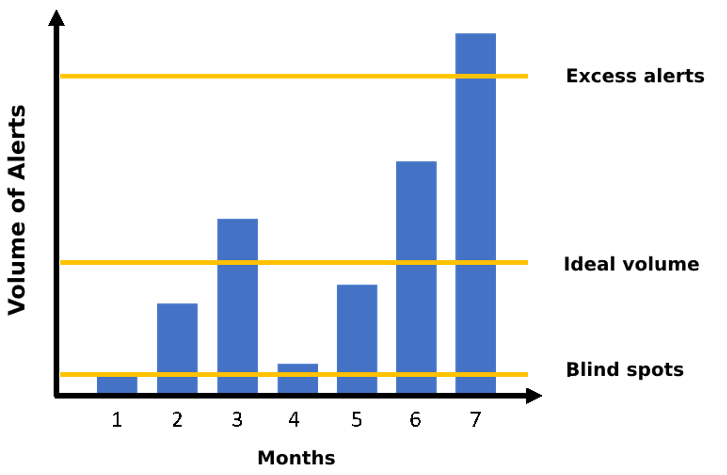
In the process of monitoring and detecting threats [6], there are two extremes:
- Too many alerts that will leave analysts overwhelmed and often failing to look at what is actually bringing risk to the business;
- Too few alerts (not even false positives) which may indicate that the environment is not being monitored correctly, as we may be blind to certain points. Examples of blind spots:
- Lack of data sources, i.e. the necessary logs aren’t being collected;
- Poorly configured tools that don’t generate useful logs to be monitored;
- Poor management of exception lists, i.e. there’s a very permissive list that ends up classifying several situations as exceptions.
The ideal volume will depend on a number of factors such as the number of assets monitored, the number of security tools available, the number of data sources being monitored, among others. We need to understand that some of the alerts generated may be false positives, so we must learn from them and manage them so that they don’t affect the investigation of others.
When we look at this issue from a detection engineering perspective, we may have a conflict between the detection opportunities identified and the false positives mapped, because often the behavior identified as malicious matches the behavior of a system administrator. Example: MITRE ATT&CK has technique T1087.002 – Account Discovery: Domain Account [7], which refers to the procedure of listing accounts and groups in a domain. This technique can be used by attackers to discover information about the environment and progress to the next stages of their attack, but this procedure can also be used by an administrator who needs to consult information about a particular user in AD (Active Directory). In this scenario, how can we differentiate malicious behavior from benign behavior?
One possibility is that, assuming the attacker doesn’t know the accounts of the users in this environment, he’ll execute this command several times to collect as much information as possible, perhaps even automating this task through a script. In this way, we can create a detection by observing the volume of processes created that have specific commandline arguments considering a certain period of time, for example: 30 commands executed in 5 seconds. This way, we can identify a threat scenario where the attacker is discovering users through an automated tool.
Therefore, we can define a detection opportunity as: one or a combination of a few pieces of evidence collected from a device that indicate a possible compromise and, whenever possible, don’t generate a false positive.
Another important point is the constant management of security tools, as they will naturally have false positives and for this we need to develop processes to help manage these alerts. For example:
Antivirus
An antivirus tool can work in different ways, whether using a signature base, heuristics, observing behavior or even machine learning to detect malicious patterns, the solution manufacturer is responsible for managing and feeding this knowledge base to detect new threats.
Nowadays, companies need to develop applications to support their business processes and these can perform procedures on actives which are the same as those of a malware, such as creating new processes or executing commands to copy files. The antivirus tool won’t recognize that this is a legitimate application and will generate an alert.
The solution to this problem is to map the alerts generated by the tool and understand the standard and expected behavior of the application. After this, exception rules can be created so that new alerts aren’t generated.
WAF (Web Application Firewall)
The WAF tool also works on the basis of signatures provided by the equipment manufacturers. In fact, many of these tools have a learning mode that aims to understand and learn the behavior of applications, making it easier to differentiate standard behavior from malicious behavior. Another common practice is to create specific policies for each application, where exceptions are added for expected behavior that the tool has identified as malicious.
IDS (Intrusion Detection System) and IPS (Intrusion Prevention System)
Like the other tools, these also work on the basis of signatures, but with the aim of identifying malicious traffic on the network. IDS only detects malicious patterns, while IPS can detect and block these communications, and it’s very common to create policies for environments and exceptions for network communications that generate false positive alerts.
Vulnerability Scanner
This tool aims to identify vulnerabilities in company assets. There are various methods for validating whether a piece of equipment is vulnerable, such as checking the version of the installed package against the tool’s knowledge base. Another possibility is to run procedures on the equipment waiting for a specific response and if it takes longer than normal, this could indicate that the equipment is vulnerable. Example: Time-based Blind SQL Injection [8].
Other factors that can lead to a false positive during vulnerability scanning are a lack of proper permissions, where the tool has access to partial information, authentication failures (when agents aren’t used) and routines that aren’t executed because there has been no communication with the target machine.
All the tools mentioned above can generate false positives if they aren’t properly managed. As we saw earlier, it’s from this information that we can build the detection logic implemented in the SIEM.
Managing False Positives
A good threat monitoring and detection process needs to include monitoring through metrics (KPIs) of false positives and even a flow for dealing with these alerts, but first we need to understand how false positives can occur in this process. Listed below are 4 false positive scenarios that can happen:
1 – Threat Scenario
Problem: By studying the MITRE ATT&CK TTPs (Tactics, Techniques and Procedures), we can envision various threat scenarios. In this example, we’ll focus on the T1110 – Brute Force technique and imagine that several authentication failure alerts have arrived on the web application server. We automatically relate this behavior to a possible brute force, but by analyzing the event we discover that the source IP belongs to the vulnerability scanning tool. Another example would be an alert related to the T1030 – Data Transfer Size Limits technique, which is normally associated with an information exfiltration procedure, but could also be a very similar behavior of a backup solution.
Solution: Create exceptions according to the mapping of standard behaviors of the environment being monitored. If the volume of false positives is high, the detection rule can be disabled until adjustments are made.
2 – Detection Logic
Problem: Detection logics serve as the basis for implementing the detection rule in the SIEM. When designing the logic, we often don’t have access to the complete procedure carried out by the attacker or the malicious artifact used during the attack. For this reason, we can map a pattern that is not necessarily malicious. Another problem could be that the logic has an objective, but is actually generating alerts for other situations.
Solution: The detection logic needs to be adjusted based on the threat scenario and procedure analyzed.
3 – Detection Rule
Problem: The detection rules that are implemented in SIEM can be derived from detection logic, depending on the company’s strategy and organizational structure. Therefore, if the objective, data source used and other information in the logic is not understood, there’s a risk that the rule will be implemented incorrectly. There may also be customizations at the time of implementation, which could lead to false positives if no prior analysis is carried out.
Solution: The rule needs to be adjusted according to the logic developed.
4 – Passthrough (security tools)
Problem: As we saw earlier, security tools are great sources of data to find out if any malicious activity is taking place in the environment, but blindly trusting the alert generated by the tool can be a mistake.
Solution: In this case, we recommend reviewing the tool’s settings so that it doesn’t generate false positives. It may be necessary to create exception rules or involve the manufacturer.
5 – Wrong analysis
Problem: In the process of managing information security incidents, we must first evaluate the events generated, putting them into context and correlating them with other information. If this doesn’t happen, the analyst may hastily indicate that the alert generated is a false positive.
Solution: Create processes and adopt the use of playbooks and runbooks to help analysts respond to incidents. Standardized handling will speed up the response and reduce the occurrence of errors when classifying alerts.
Each false positive scenario may require specific activities carried out by different teams. Having a communication flow between the teams will help analysts make decisions during the process of screening and classifying alerts. Below is an example of such a flow:
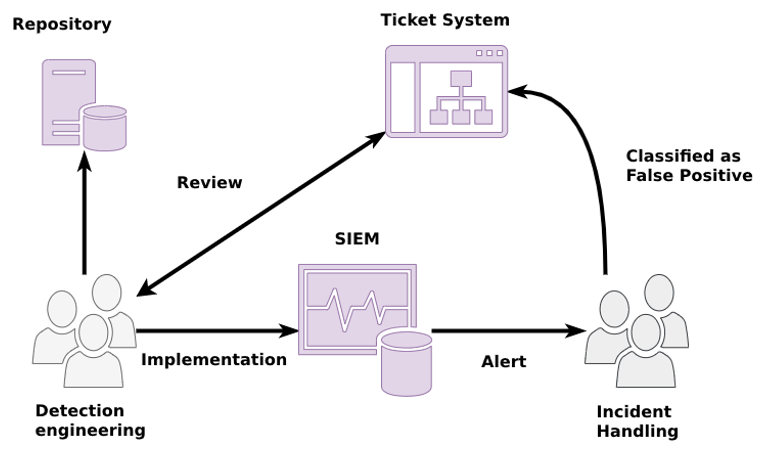
The more automated this flow is, the faster the teams involved can correct the problem. We can mention the example of false positive alerts linked to an IoC (Indicator of Comprise). If an IoC management tool such as MISP-broker [9] is used, the incident response analyst can easily indicate via the MISP system that a particular IoC has generated a false positive alert and it will be removed from the SIEM automatically. We can also establish DevOps processes for creating detection rules, speeding up the correction and implementation of the corrected version.
Another item that should be established is a KPI to track the rate of false positives over the course of the month:
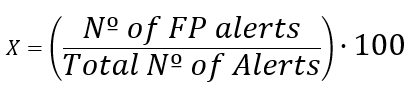
The result is expressed as a %. Below is an example of how to interpret this data:
- 0% – 5%: normal and expected behavior for an average volume of 100,000 events per month (example);
- 1% – 15%: false positives should be evaluated to understand the root cause, where processes and configurations should be adjusted;
- greater than 15.1%: a systematic review of the processes and tools involved in the incident monitoring and response process is required.
As stated above, each environment will be made up of different technologies and monitoring processes, so the percentages specified above should be evaluated for the context of your process.
We can also establish other indicators to track these alerts, such as:
- Percentage of FP alerts per implemented rule: with this value we can identify which rules are generating the most false positives;
- Percentage of FP alerts per scenario: assessing whether the threat scenario being monitored makes sense for the business;
- Total hours spent on FP analysis: we can identify the cost generated by hours dedicated to dealing with false positives;
- Number of alerts categorized as FP but which ended up generating an incident: this is part of the continuous improvement process, where we must learn from the operational mistakes made.
When we talk about SIEM rules, we can document a series of metadata that will help the other SOC teams understand the purpose and operation of the rule, such as:
- Mapped false positives: during the rule creation process, if a false positive is mapped, this should be documented so that the incident response team is aware of it during the alert assessment;
- Type of rule: we can have rules with different goals, i.e. more specific rules that identify a TTP and can generate an alert, while more comprehensive rules that can generate false positives can be used to perform a hunting in the environment. This differentiation means that the SOC does not fail to map malicious events and separates alerts from other analyses that can be carried out in the environment;
- Volume: this is difficult information to evaluate, but if it can be identified based on past events, we can document the volume of alerts expected for a given rule. Example: low, medium or high;
- Timeframe for analysis: this device is already used to define some malicious patterns, such as 300 authentication failures in 2 seconds, but if we see that the volume of events is high, but it still makes sense to monitor, we can tell SIEM to check the logs every x time, where x is a value in minutes or hours;
- Visibility: we can also say that the alert generated for this rule doesn’t need to be forwarded to an incident response analyst to deal with. Instead, it can appear on a dashboard or report to be evaluated later. We usually use this option for alerts related to business rules.
Conclusion
In this article, we have presented the concepts related to false positives in the context of cyber threat detection, how we can deal with them and, most importantly, how we can manage them knowing that it is to be expected that they will occur in the process of monitoring and responding to security incidents. As explained, we need to establish processes and indicators so that false positives are tracked and don’t generate operational costs, either in the misclassification of the event that could become a critical incident or in the overloaded security operation due to too many alerts.
References
[1] Tempest Security Intelligence, “Desvendando o SIGMA (yaml) para engenharia de detecção”, September 30, 2021. Available at: https://sidechannel.blog/desvendando-o-sigma-yaml-para-engenharia-de-deteccao/
[2] The MITRE Corporation, “11 Strategies of a World-Class Cybersecurity Operations Center”, March 31, 2022. Available at: https://www.mitre.org/sites/default/files/ 2022-04/11-strategies-of-a-world-class-cybersecurity-operations-center.pdf
[3] Wikipedia, “Binary Classification”, November 2, 2022. Available at: https://en.wikipedia.org/wiki/Binary_classification
[4] NIST, “False Positive”, July 03, 2019. Available at: https://csrc.nist.gov/glossary/term/false_positive
[5] NIST, “False Negative”, July 03, 2019. Available at: https://csrc.nist.gov/glossary/term/false_negative
[6] SANS, “When Being Wrong is Right The Role of False Positives in Building a Detection Pipeline”, October 21, 2019. Available at: https://www.sans.org/presentations/when-being-wrong-is-right-the-role-of-false-positives-in-building-a-detection-pipeline/
[7] The MITRE Corporation, “T1087.002 – Account Discovery: Domain Account”, August 25, 2022. Available at: https://attack.mitre.org/techniques/T1087/002/
[8] OWASP, “Blind SQL Injection”, October 5, 2020. Available at: https://owasp.org/www-community/attacks/Blind_SQL_Injection
[9] Tempest, “Indicadores de Comprometimento na detecção de incidentes e redução de falso positivos na prática”, August 5, 2022. Available at: https://sidechannel.blog/indicadores-de-comprometimento-na-deteccao-de-incidentes-e-reducao-de-falsos-positivos-na-pratica/