Por Paulo Freitas de Araujo Filho
Este é o quarto post do nosso blog da série “Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning”, onde discutimos o uso da aprendizagem de máquina em sistemas de detecção de intrusão (IDSs). Em nosso post anterior, discutimos algoritmos de detecção de intrusão tradicionais baseados em one-class novelty detection, que são treinados com amostras de dados de apenas uma classe e detectam anomalias medindo desvios dessa classe. Agora, vamos um pouco mais longe, focando em uma estrutura de deep learning chamada autoencoder que também pode ser usada como um método de one-class novelty detection para IDSs.
Algoritmos one-class novelty detection são particularmente interessantes quando é difícil (ou caro) ter exemplos de dados rotulados de todas as classes. Por exemplo, embora possa ser fácil ter muitos dados benignos de redes e sistemas, geralmente é muito difícil e caro ter exemplos de dados de atividades maliciosas. Entretanto, algoritmos tradicionais de uma classe, como o one-class support vector machine (OCSVM) [1] e o isolation forest [2], exigem muito esforço para selecionar e extrair features. Técnicas baseadas em deep learning, por outro lado, superam esta limitação selecionando e extraindo automaticamente as features que garantem os melhores resultados [3], [4].
Autoencoders
Autoencoders são estruturas de deep learning que foram originalmente desenvolvidas para compressão de dados [4]-[7]. Eles consistem em uma rede neural que pode ser dividida em duas partes: codificador e decodificador. O codificador compreende as primeiras camadas da rede neural, que têm o objetivo de reduzir a dimensionalidade dos dados. Ou seja, ele codifica os dados de entrada em representações de dados com dimensões menores. Por exemplo, uma imagem com dimensões 128×128 pode ser codificada em uma representação comprimida com dimensões 32×32. De maneira análoga, qualquer vetor, que pode conter dados de redes e sistemas, por exemplo, pode ser comprimido com um autoencoder.
Por outro lado, a parte decodificadora do autoencoder faz a tarefa oposta. Ela reconstrói os dados de entrada originais a partir de sua representação comprimida. Assim, o autoencoder codifica padrões de dados em representações de menor dimensão e depois os reconstrói para que tenham as mesmas dimensões das entradas originais e pareçam o máximo possível com elas [5]-[7]. Entretanto, como se pode esperar, pode haver alguma diferença entre os dados de entrada originais e suas reconstruções, essas diferenças são chamadas de erros de reconstrução [7]-[9]. A Figura 1 ilustra a estrutura de um autoencoder que codifica e decodifica imagens de cogumelos.
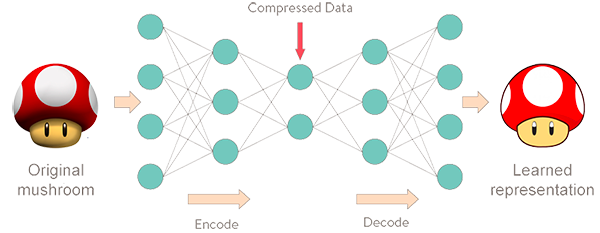
A Figura 2 ilustra visualizaçĩes típicas de imagens reconstruídas por um autoencoder.

Ok, parece interessante. Mas como essa estrutura de autoencoder pode ser usada para detectar intrusões? Tudo se resume aos dados de treinamento. Tomemos o exemplo da Figura 1, na qual o autoencoder foi treinado com imagens de cogumelos. Se usarmos o autoencoder para reconstruir uma imagem de cogumelo, mesmo que seja uma imagem desconhecida e nunca vista antes, o erro de reconstrução será pequeno, pois esse autoencoder aprendeu como são os cogumelos. Entretanto, se dermos uma imagem de um cachorro ao autoencoder, ele terá um erro de reconstrução maior, pois não foi treinado com imagens de cães, ou seja, não sabe como comprimir e reconstruir imagens de cães. Assim, seguindo essa mesma ideia, se o autoencoder for treinado apenas com dados benignos de redes e sistemas e mais tarde for colocado para reconstruir as amostras de dados recebidos, ele produzirá pequenos erros de reconstrução para as amostras que são benignas e grandes erros de reconstrução para as amostras que são maliciosas. Vários trabalhos de pesquisa vêm explorando essa estratégia para detectar ataques cibernéticos [8]-[11].
Variational Autoencoders
Existem também variações na estrutura dos autoencoders que os melhoram de diferentes maneiras. Dentre elas, os variational autoencoders (VAE) melhoram os autoencoders através da modelagem de dados com distribuições estatísticas. Enquanto autoencoders tradicionais constroem uma representação fixa de amostras de dados que os mapeia em versões com dimensões reduzidas de si, VAEs modelam o espaço de dimensões reduzidas de acordo com uma distribuição estatística com média μ e desvio padrão σ [5], [12], [13]. Ou seja, ao invés de simplesmente mapear amostras de dados em padrões comprimidos com o codificador do autoencoder, o VAE encontra qual distribuição de dados pode representar todos os dados comprimidos. Esta propriedade nos permite obter vetores aleatórios dessa distribuição, independentemente de qual entrada os produziria, e usar o decodificador do VAE para produzir novas amostras de dados. Assim, o VAE não só reconstrói amostras de dados, como também tem a capacidade de gerar novas amostras [5], [12], [13].
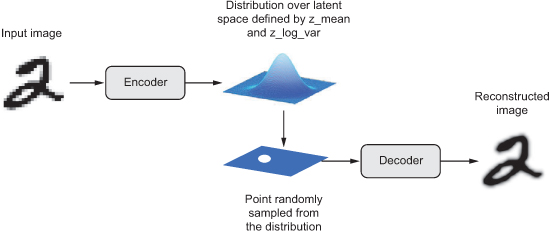
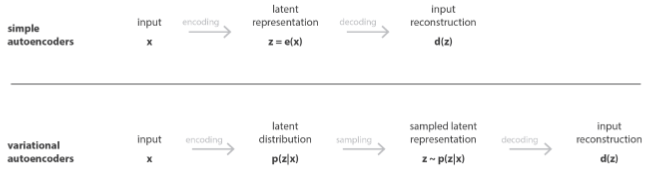
Da mesma forma que ao utilizar autoencoders tradicionais, VAEs podem ser treinados apenas com dados benignos de redes e sistemas para que aprendam os seus padrões normais e detectem amostras maliciosas através do erro de reconstrução das amostras. Pequenos erros indicam que as amostras avaliadas pertencem à mesma categoria dos dados de treinamento, ou seja, os dados benignos. Grandes erros de reconstrução, por outro lado, indicam que as amostras avaliadas não pertencem à categoria dos dados de treinamento, ou seja, são anomalias que podem ser o resultado de atividades maliciosas [7]. Estudos recentes mostram que VAEs vêm superando autoencoders tradicionais na detecção de ciberataques [12], [13]. A Figura 3 mostra a estrutura do VAE e a Figura 4 a compara à estrutura do autoencoder tradicional.
Colocando em prática
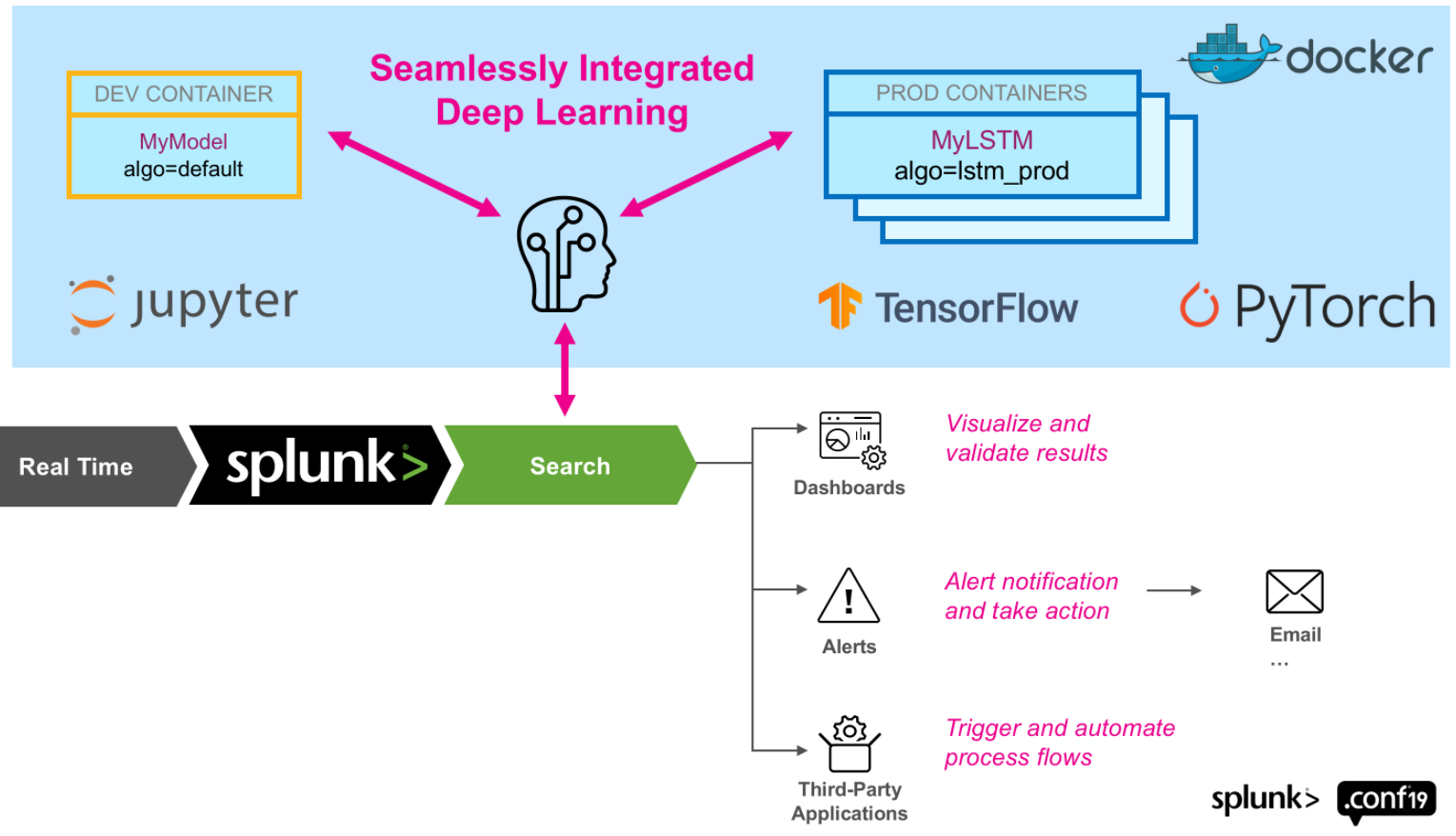
O Splunk, que é uma das plataformas mais utilizadas de gerenciamento de informações de segurança e eventos (SIEM), reúne, gerencia e correlaciona dados bem como implementa regras de detecção de ataques cibernéticos. A ferramenta deep learning toolkit (DLTK) do Splunk oferece grande flexibilidade ao integrar o Splunk com um container para que seja possível implementar algoritmos de deep learning, tais como autoencoders e VAEs, treiná-los e implantá-los como se fossem regras tradicionais de detecção de ataques cibernéticos. A Figura 5 ilustra a integração entre o Splunk e um ambiente docker com suporte para as estruturas de aprendizagem profunda mais comuns, TensorFlow e Pytorch. Para maiores informações, por favor, consulte [14] e [15].
Assim, autoencoders e VAEs podem ser implementados e implantados usando o DLTK do Splunk para que sejam treinados apenas com dados benignos de, por exemplo, logs de firewall. Então, os modelos treinados podem ser configurados como regras para alertar como suspeitos os logs de firewall que produzem erros de reconstrução maiores que um valor limite definido. A Figura 6 mostra uma amostra de log de firewall.

A Figura 7 mostra três dados de logs de firewall que são detectados como suspeitos por um autoencoder devido aos seus altos erros de reconstrução, que são retratados na última coluna da Figura 7 como “predicted_0”.

Desafios e obstáculos
Embora IDSs baseados em autoencoders e VAEs venham mostrando resultados muito promissores na detecção de ciberataques, eles exigem que apenas amostras de dados benignos sejam usadas no seu treinamento. Assim, como os algoritmos de one-class novelty detection tradicionais, eles devem primeiro considerar outras técnicas, como clustering, para garantir que somente amostras benignas sejam usadas no treinamento. Caso contrário, o modelo treinado poderia ser levado a acreditar que amostras maliciosas são benignas.
Conclusão
Neste post, discutimos IDSs que utilizam autoencoders para detectar anomalias através de erros de reconstrução. Precisamente, grandes erros de reconstrução representam não conformidades das amostras avaliadas com os dados de treinamento benigno, de modo que indicam atividades maliciosas. Na Tempest, estamos investigando e utilizando tais técnicas para melhor proteger os nossos clientes! Fique atento ao nosso próximo post!
Referências
[1] V. Chandola, A. Banerjee, and V. Kumar, ‘‘Anomaly detection: A survey,’’ ACM Comput. Surv., vol. 41, no. 3, p. 15, 2009
[2] F. T. Liu, K. M. Ting, and Z.-H. Zhou, ‘‘Isolation-based anomaly detection,’’ ACM Trans. Knowl. Discovery Data, vol. 6, no. 1, pp. 3:1–3:39, Mar. 2012.
[3] P. Freitas de Araujo-Filho, G. Kaddoum, D. R. Campelo, A. Gondim Santos, D. Macêdo and C. Zanchettin, “Intrusion Detection for Cyber–Physical Systems Using Generative Adversarial Networks in Fog Environment,” in IEEE Internet of Things J., vol. 8, no. 8, pp. 6247-6256, 15 April15, 2021, doi: 10.1109/JIOT.2020.3024800.
[4] J. Schmidhuber, “Deep learning in neural networks: An overview,” Neural Netw., vol. 61, pp. 85–117, 2015.
[5] B. Pesquet. Autoencoders. Acesso: 22 de abril, 2022. [Online]. Disponível em: https://www.bpesquet.fr/mlhandbook/algorithms/autoencoders.html
[6] D. Dataman. Anomaly Detection with Autoencoders Made Easy. Acesso: 22 de abril, 2022. [Online]. Disponível em: https://towardsdatascience.com/anomaly-detection-with-autoencoder-b4cdce4866a6
[7] R. Khandelwal. Anomaly Detection using Autoencoders. Acesso: 22 de abril, 2022. [Online]. Disponível em: https://towardsdatascience.com/anomaly-detection-using-autoencoders-5b032178a1ea
[8] M. Gharib, B. Mohammadi, S. Hejareh Dastgerdi, and M. Sabokrou, ‘‘AutoIDS: Auto-encoder based method for intrusion detection system,’’ 2019, arXiv:1911.03306. [Online]. Disponível em: http://arxiv.org/abs/1911.03306
[9] Yisroel Mirsky, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai. Kitsune: an ensemble of autoencoders for online network intrusion detection. arXiv preprint arXiv:1802.09089, 2018.
[10] F. Farahnakian and J. Heikkonen, “A deep auto-encoder based approach for intrusion detection system,” 2018 20th International Conference on Advanced Communication Technology (ICACT), 2018, pp. 178-183, doi: 10.23919/ICACT.2018.8323688.
[11] R. Zhao et al., “An Efficient Intrusion Detection Method Based on Dynamic Autoencoder,” in IEEE Wireless Communications Letters, vol. 10, no. 8, pp. 1707-1711, Aug. 2021, doi: 10.1109/LWC.2021.3077946.
[12] J. Rocca. Understanding Variational Autoencoders (VAEs). Acesso: 22 de abril, 2022. [Online]. Disponível em: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
[13] S. Zavrak and M. İskefiyeli, “Anomaly-Based Intrusion Detection From Network Flow Features Using Variational Autoencoder,” in IEEE Access, vol. 8, pp. 108346-108358, 2020, doi: 10.1109/ACCESS.2020.3001350.
[14] D. Federschmidt, P. Salm, L. Utz, G. Ainslie-Malik, P. Drieger, A. Tellez, P. Brunel, R. Fujara, “Splunk App for Data Science and Deep Learning (DLTK)”, Acesso: 23 de junho, 2022. [Online]. Disponível em: https://splunkbase.splunk.com/app/4607/#/details
[15] D. Lambrou, “Splunk with the Power of Deep Learning Analytics and GPU Acceleration”, Acesso: 23 de junho, 2022. [Online]. Disponível em: https://www.splunk.com/en_us/blog/tips-and-tricks/splunk-with-the-power-of-deep-learning-analytics-and-gpu-acceleration.html
Outros artigos dessa série:
Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning
Parte 1 de 5: Sistemas de Detecção de Intrusão baseados em Assinaturas versus Anomalias
Parte 2 de 5: Sistemas de Detecção de Intrusão Não Supervisionados usando Clustering
Parte 3 de 5: Sistemas de Detecção de Intrusão baseados em One-Class Novelty Detection
Parte 4 de 5: Detecção de Intrusão usando Autoencoders
Parte 5 de 5: Detecção de Intrusão usando Generative Adversarial Networks