By Renato Alpes
This post is the result of the last stage of a consultancy internship cycle at Tempest: a research project on a security-related topic. Guided by my research advisor Jodson Leandro and my compass Nikolaos Eftaxiopoulos, I chose a topic that was close (at least initially) to the hardware area, the one I had the most contact with during graduation. The study eventually took a path that distanced it from the initial idea, but the important thing is that everything worked out in the end and I finished the first cycle of the internship with much more knowledge than when I started. That said, let’s move on to a brief introduction to the technologies discussed in this research.
The personal voice assistant Alexa, launched by Amazon in 2014, is present on more than 100 million devices [1]. Most of these users interact with Alexa through an Echo device, such as the Amazon Echo Dot 3, which was used to test the proof-of-concept attacks in this post.
The Echo Dot 3 is a bluetooth speaker designed specifically to be used as an interface with Alexa and it looks like this:

The feature which is the focus of this research is called Alexa Skills and allows third-party developers to add customized functionality to Alexa in a similar way as an app. Before a user can utilize an Alexa Skill, it needs to be activated. This can be done manually via the companion app that controls the Echo, or via a voice command. Activation by voice command can happen in two ways: intentionally, i.e. the user explicitly speaks aloud the activation phrase specified by the skill; or inferentially, i.e. the user makes a request that Alexa cannot fulfill with its standard functionalities and Alexa activates a skill that it considers capable of completing the request.
Once the skill is activated, the user can interact with it using the voice model defined by the skill’s developer. This model consists of at least three parts: an Invocation Name, which is the name used by the user to start the skill; one or more Utterances, which are phrases defined by the developer that will be mapped to an Intent; and one or more Intents, which are objects that define a user intention. Certain Intents can also contain one or more Slots, which are extra pieces of information (such as a phone number or color) that will be used in the processing of that Intent.
With these definitions outlined, it’s possible to break down the workings of a user interaction with any skill:
- The user utters a sentence starting with Alexa’s wake-up word (“Alexa”, by default): “Alexa, open Spotify and play Idol by Yoasobi”
- The Echo Dot recognizes the wake-up word, records it until the user stops talking and sends the result to the Alexa Service on Amazon’s servers. The audio file is then processed by an Automated Speech Recognition algorithm, returning a transcript that is sent to a Natural Language Understanding algorithm.
- The NLU recognizes the requested skill through the Invocation Name used (in this case, “Spotify”) and uses the voice model previously defined to link the Utterance “Idol ringtone by Yoasobi” to the Intent “PlaySong”. The definition of this Intent includes the “Song” and “Artist” Slots, which are filled with “Idol” and “Yoasobi” respectively.
- The Intent object generated by the previous step is encapsulated in a JSON that is sent in an HTTP POST request to the backend specified by the developer (usually an AWS lambda function).
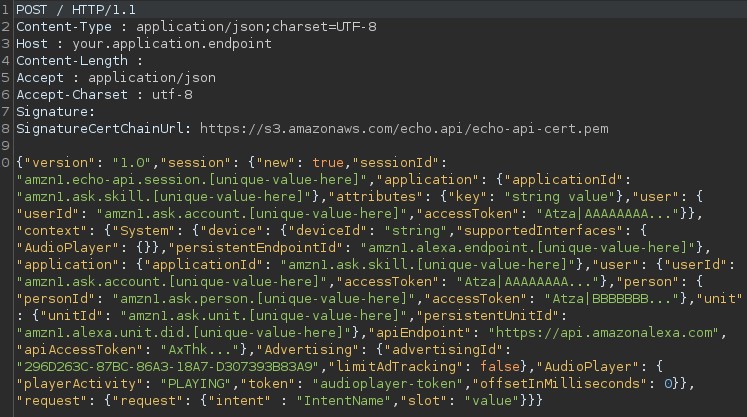
- The backend responds with a JSON containing the “response” object, which is made up of various parameters that indicate what Echo should respond to the user with. In this case, the “outputSpeech” functionality is used, which will read out a text of the “plainText” type.
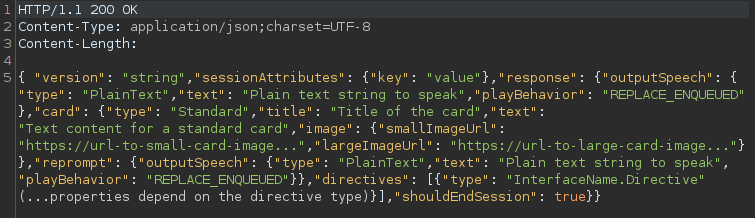
- The Alexa Service sends the response to be spoken to the user by the Echo and the audio file to be played.
- The Echo Dot speaks aloud “Playing Idol by Yoasobi” and starts playing the song.
The skill development process can be carried out entirely in the Alexa developer console, with the developed skill having to go through a certification process before being published.
Attack surface
Putting together the observations made, we can create a list of points that can be controlled by an attacker and behaviors at these points that can be used to generate a specific effect.
Bluetooth Connection
The device’s pairing mode can be activated by voice (“Alexa, bluetooth” is enough) and doesn’t ask for any authorization before pairing, allowing an attacker with physical access to some environment near the device to connect and take control of the speaker. In an attack using this vulnerability, an attacker could, for example, shout “Alexa, bluetooth” through an open window and gain remote control of the speaker to use for exploiting other vulnerabilities.
Voice command recognition
Although the device is able to recognize whether the voice of the person speaking belongs to a previously registered user, the default behavior allows any speech recorded by the device to be understood as a command, including third parties who have never been encountered by the device before. In addition, the device recognizes commands sent through its own speaker as legitimate commands. This allows an attacker who has gained control of the speaker through some other vulnerability to send voice commands that will be executed by the device.
Skill Activation
The skill activation step is crucial for any attack capable of doing more than just controlling the speaker. An attacker interested in getting a target user to activate a particular skill can use a combination of some of the following behaviors:
- the device performs the activation of any skill whose activation phrase has been enunciated, without confirming with the user that this was indeed its intention. In this way, it’s possible to create a skill with an activation phrase commonly used in everyday life (for example: “Good morning”);
- the Alexa Service automatically activates skills that return a response with a positive CanFulfillIntent object when a user makes a request without using a trigger phrase that specifies a particular skill. This behavior allows an attacker to create a skill that always returns CanFullfillIntent = true, increasing the chances that their skill will be executed automatically;
- the skill development ecosystem allows skills to be created with activation phrases with identical pronunciation to existing skills. In addition, the algorithm doesn’t prioritize older or previously activated skills when deciding which skill the user would like to activate;
- flaws in Amazon’s API have already allowed an attacker to activate arbitrary skills by simply clicking on a malicious link.
Skill execution
The execution of a skill can be carried out on a server under the complete control of its developers, so it’s impossible to guarantee that the skill’s behavior hasn’t been modified after the publishing and certification process. Furthermore, even when using Amazon’s host services, developers can easily circumvent the use of the APIs that Amazon makes available to collect sensitive information from users (such as address and telephone number) by obtaining the information directly. Finally, during the tests conducted, the device didn’t alert the user in any way, even when the skill’s response was silent for more than nine minutes.
User response
The system used to send responses to the user allows arbitrary responses to be sent, and more specifically, it allows empty responses to be sent (characters that generate a long period of silence, such as the <break/> directive) or even arbitrary audio files to be played by the speaker (a vulnerability known as the full-volume vulnerability allows audio sent to be played at maximum volume). In addition, a developer can modify the response to common Intents such as help, stop and cancel. An attacker can use these behaviors to make users believe that the interaction with the skill is over, when in fact the listening is still active, or to make users believe that they are talking to Alexa, when in fact they are interacting with a skill.
Attacks
Through a combination of the aforementioned behaviors, different types of attacks can be carried out with different scenarios and objectives.
Certification bypass
The following flowchart demonstrates an attack used by researchers to publish skills with undesirable functionality in the store:
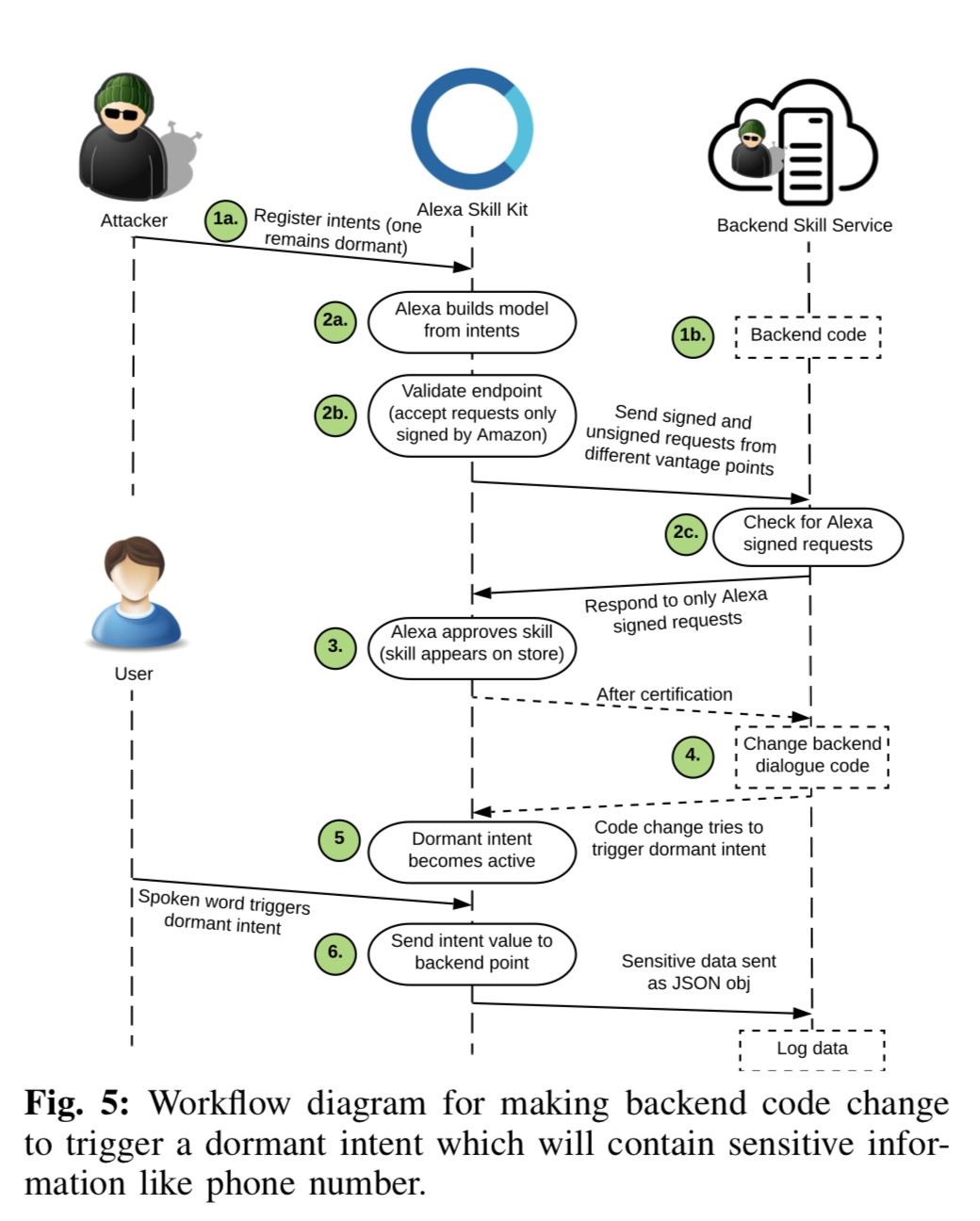
This bypass is essential for targeting ordinary users with malicious skills.
Skill Squatting
In this attack, the attacker uses the automatic activation of skills and the possibility of using activation phrases with phonetic collisions to execute a skill with arbitrary functionality. The attack works as follows:
- user activates the G1 news skill in the store;
- attacker creates a skill with Invocation Name “g. um”;
- attacker publishes his skill in the store;
- user says “Alexa, open G1”;
- attacker’s skill is activated and executed;
Alexa vs Alexa
This attack uses the vulnerability that allows Echo to interpret commands sent through the speaker itself combined with the full-volume vulnerability to control the device remotely. The audio file used to launch the attack can be played via Bluetooth or a malicious radio skill.
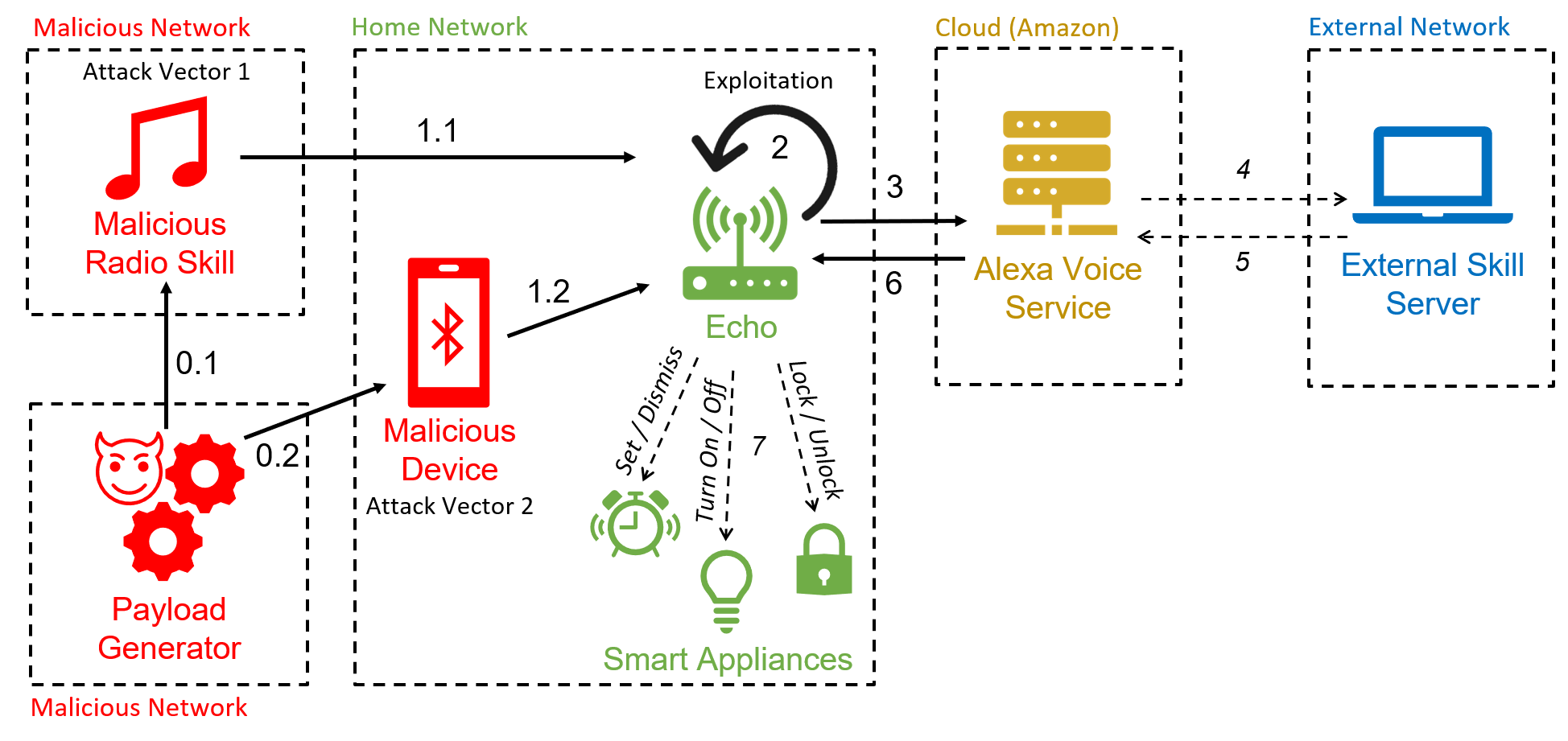
The attack works as follows:
- attacker prepares the malicious audio using a text-to-speech service;
- attacker connects to the vulnerable Echo via bluetooth;
- attacker plays the audio on the Echo Dot;
- speaker plays: “Alexa, turn off [pause] Alexa, what time is it?”;
- echo recognizes and executes an arbitrary command.
This attack’s results allow an attacker to control smart home applications, edit account calendars, answer and delete emails, make phone calls, make purchases on Amazon (using previously obtained PINs), invoke other skills, etc.
Mask Attack
This attack uses the attacker’s control over the response sent to the user to create the illusion that the target user is communicating with Alexa, when in fact they are interacting with a malicious skill. The attack works as follows:
- Malicious skill is executed.
- Backend receives the LaunchIntent.
- Backend responds to the Intent with an arbitrary amount of the SSML break tag: “<break/><break/><break/><break/><break/>…”
- Skill remains listening for the duration of the response.
- User performs an interaction: “Alexa, what’s the weather like in Recife?”
- Skill receives each word as a filled InterceptIntent slot.
- Backend forwards the request to the Amazon API and returns the response.
- Sensitive information is stored in the backend.
The consequences of this attack include the capture of sensitive information such as passwords, PINs and credit card numbers, as well as phishing attacks and the capture of Echo usage information.
Bypass of API sensitive information
Social engineering techniques allow a developer to obtain sensitive information without obtaining proper permission and without publishing a privacy policy for the use of the data.
Conclusion
A sufficiently determined attacker is able to use the techniques demonstrated in this post to gain control of any Echo Dot device, or even a particular device, in order to obtain sensitive information or carry out undesirable actions. However, the flow of attacks is complex and requires user interaction at several points.
References
A. Sabir, E. Lafontaine, A. Das (2022). “Hey Alexa, Who Am I Talking to?: Analyzing Users’ Perception and Awareness Regarding Third-party Alexa Skills”
Alexa, Google Home Eavesdropping Hack Not Yet Fixed | Threatpost Accessed in January 2023.
[1] Amazon.com Announces Third Quarter Results Accessed in January 2023.
Amazon Fixes Alexa Glitch That Could Have Divulged Personal Data | Threatpost Accessed in January 2023.
Attackers can force Amazon Echos to hack themselves with self-issued commands | Ars Technica Accessed in January 2023.
C. Lentzsch, S. Shah, B. Andow, M. Degeling, A. Das, W. Enck (2021). “Hey Alexa, is this Skill Safe?: Taking a Closer Look at the Alexa Skill Ecosystem”
D. Su, J. Liu, S. Zhu, X. Wang, W. Wang (2020). ““Are you home alone?” “Yes” Disclosing Security and Privacy Vulnerabilities in Alexa Skills”
Documentation Home | Alexa Voice Service Accessed in January 2023.
How to Improve Alexa Skill Discovery with Name-Free Interaction and More Accessed in January 2023.
HypRank: How Alexa determines what skill can best meet a customer’s need – Amazon Science Accessed in January 2023.
K. M. Malik, H. Malik, R. Baumann (2019). “Towards Vulnerability Analysis of Voice-Driven Interfaces and Countermeasures for Replay Attacks”
Keeping the gate locked on your IoT devices: Vulnerabilities found on Amazon’s Alexa – Check Point Research Accessed in January 2023.
Researchers Hacked Amazon’s Alexa to Spy On Users, Again | Threatpost Accessed in January 2023.
S. Esposito, D. Sgandurra, G. Bella (2022). “Alexa versus Alexa: Controlling Smart Speakers by Self-Issuing Voice Commands”
The Scalable Neural Architecture behind Alexa’s Ability to Select Skills – Amazon Science Accessed in January 2023.
Y. Kim, D. Kim, A. Kumar, R. Sarikaya (2018). “Efficient Large-Scale Neural Domain Classification with Personalized Attention”