Introdução
Detectar ciberataques é de fundamental importância para garantir a segurança de redes e sistemas. Assim, a fim de detectar atividades maliciosas, muitas empresas utilizam plataformas de gerenciamento de informações de segurança e eventos (security information and event management – SIEM) para reunir, gerenciar e analisar dados de diferentes fontes de logs, como firewalls e sistemas operacionais. De modo geral, atividades maliciosas podem ser detectadas a partir da implementação, em SIEMs, de regras de detecção que verificam a ocorrência de padrões de atividades ou códigos correspondentes a ataques, ou seja, de assinaturas de atividades maliciosas. Contudo, embora a detecção de ataques usando assinaturas funcione bem para muitas situações, ela também apresenta problemas e limitações, como, por exemplo, dificuldade em detectar variações de ataques ou ataques desconhecidos, uma vez que não há assinaturas específicas para eles [1].
A fim de superar essas limitações, uma outra abordagem de detecção vem sendo cada vez mais adotada: a detecção de anomalias. Sistemas de detecção de anomalias modelam o comportamento normal de usuários, redes e sistemas, a fim de estabelecer padrões de comportamento normais e medir desvios desses padrões, tendo em vista que grandes desvios representam não conformidades com o comportamento normal, indicando, portanto, atividades suspeitas [2]. Nesse contexto, o uso de algoritmos de machine learning tem mostrado resultados promissores na detecção de ciberataques baseada em anomalias. Eles não dependem de assinaturas de ataques conhecidos, mas da observação e identificação de padrões nos dados, aprendendo os padrões que os dados de sistemas e redes apresentam na ausência de atividades maliciosas e até mesmo os padrões que ocorrem durante ataques [3, 4]. Convidamos todos a lerem a nossa série de blog posts Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning, nos quais abordamos como diferentes algoritmos de machine learning podem ser usados para detectar ciberataques.
Mas como implementar, treinar e colocar em execução algoritmos de machine learning em SIEMs? Felizmente, as principais empresas de SIEMs do mercado já perceberam as vantagens e benefícios trazidos pelo uso de machine learning na detecção de ciberataques, fornecendo ferramentas específicas para isso. Neste blog post, explicaremos, de maneira prática e objetiva, como implementar, treinar e colocar em prática a detecção de ataques usando machine learning no SIEM Splunk através de sua ferramenta Splunk App for Data Science and Deep Learning (DSDL), anteriormente conhecida como Deep Learning Toolkit (DLTK) [5]. Todos os códigos criados nesse blog post estão disponíveis em https://github.com/tempestsecurity/splunk_dsdl_tutorial.
Splunk DSDL
O DSDL é uma ferramenta do Splunk que o integra a um container em que podemos implementar algoritmos de machine learning desenvolvidos em um Jupyter Notebook com as principais bibliotecas e frameworks de machine learning e deep learning, como scikit-learn, Pytorch e Tensorflow. Assim, podemos implementar diversos algoritmos de machine learning já existentes e largamente usados em detecção de anomalias, bem como desenvolver e implementar os nossos próprios algoritmos. Além disso, o container pode ser executado em um docker em uma máquina diferente da que o Splunk é executado, permitindo, por exemplo, o uso de máquinas com GPUs da AWS para que se tenha uma maior capacidade de processamento no treinamento de modelos de machine learning. A Figura 1 ilustra a arquitetura do Splunk DSDL. Para mais informações, por favor verificar [6].
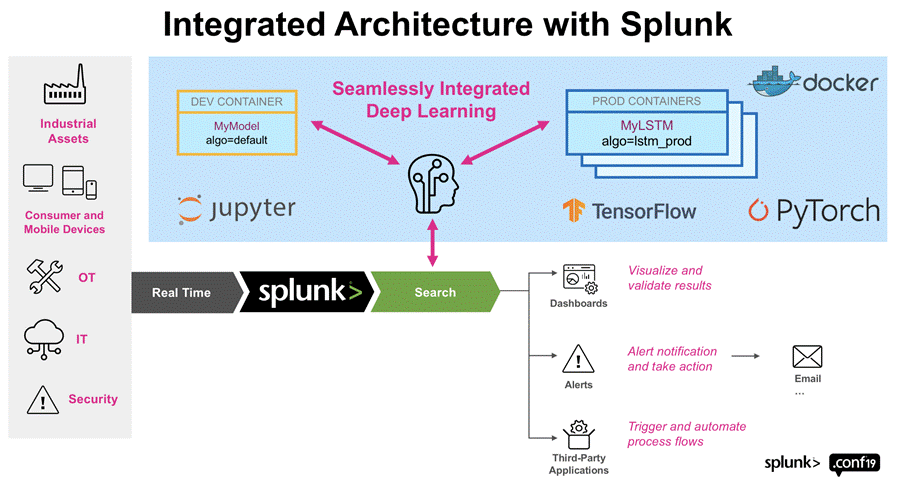
Instalando o Splunk
Pois bem, vamos iniciar o nosso tutorial. Antes de tudo, precisamos instalar o Splunk. Apesar de se tratar de uma ferramenta paga, é possível utilizá-la gratuitamente por 60 dias através de um free trial. Na verdade, mesmo depois desses 60 dias, é possível continuar usando o Splunk com uma versão um pouco mais limitada, mas que é suficiente para os exemplos que faremos neste tutorial.
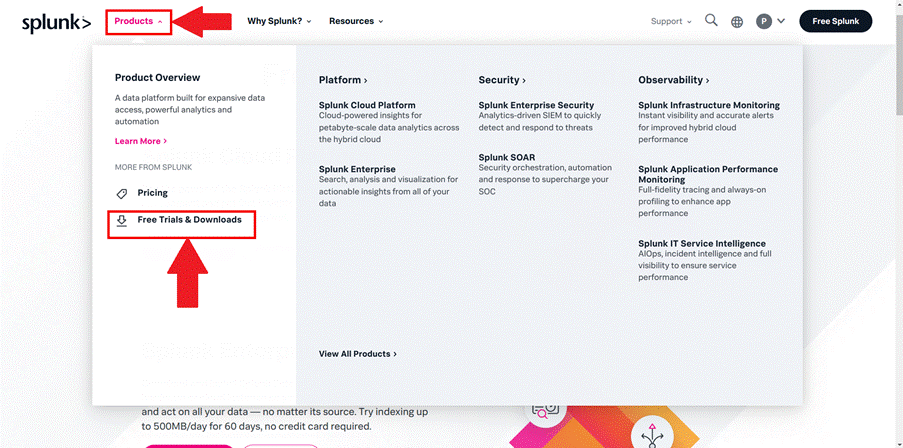
Assim, acesse o site oficial do Splunk https://www.splunk.com/, crie uma conta e faça login. Na sequência, conforme indicado na Figura 2, clique em “Products -> Free Trials & Downloads”.
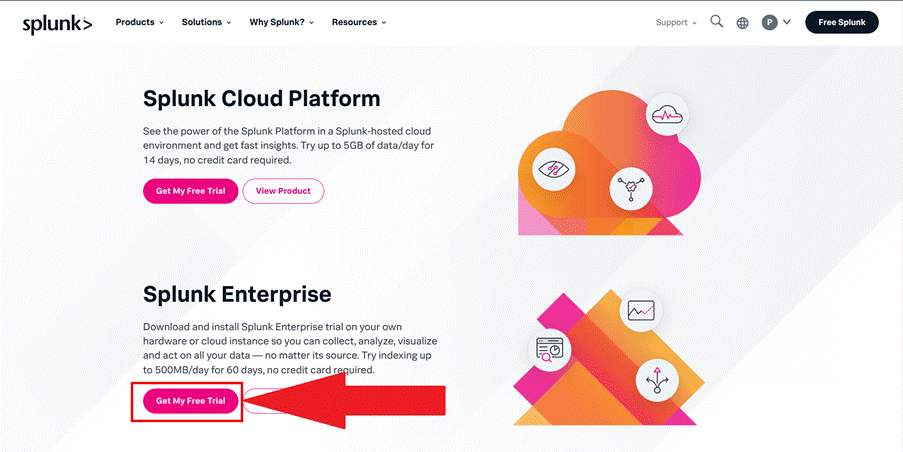
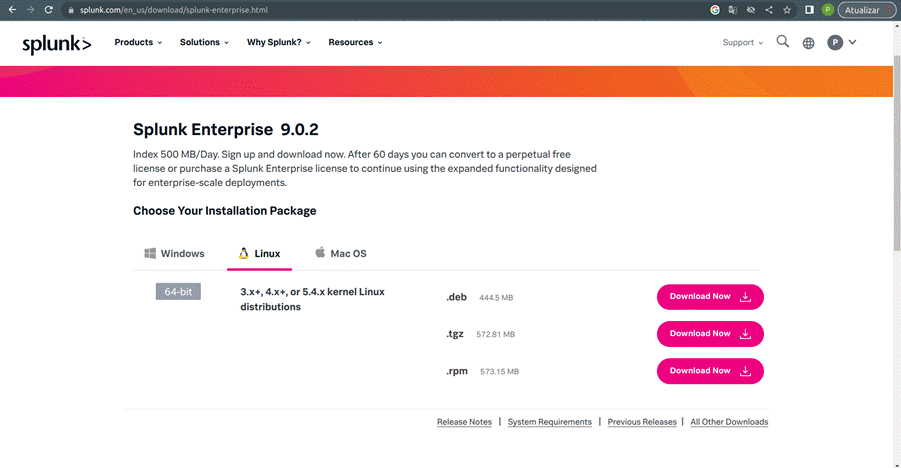
Em seguida, escolha a opção “Enterprise”, como ilustrado na Figura 3, e faça o download da opção que se adequa ao seu sistema operacional, como indicado na Figura 4.
Por fim, siga as instruções de instalação indicadas em manual de instalação para Linux, caso esteja usando Linux, ou em manual de instalação caso esteja usando outros sistemas operacionais.
Iniciando o Splunk
Uma vez instalado, inicie o Splunk conforme os passos listados abaixo.
- Abrir o terminal, navegar até o diretório em que o Splunk foi instalado e executar o comando:
$ sudo bin/splunk start

2. Ao término da execução anterior, acessar o link do servidor do Splunk usando um browser (ctrl+click no link costuma funcionar)
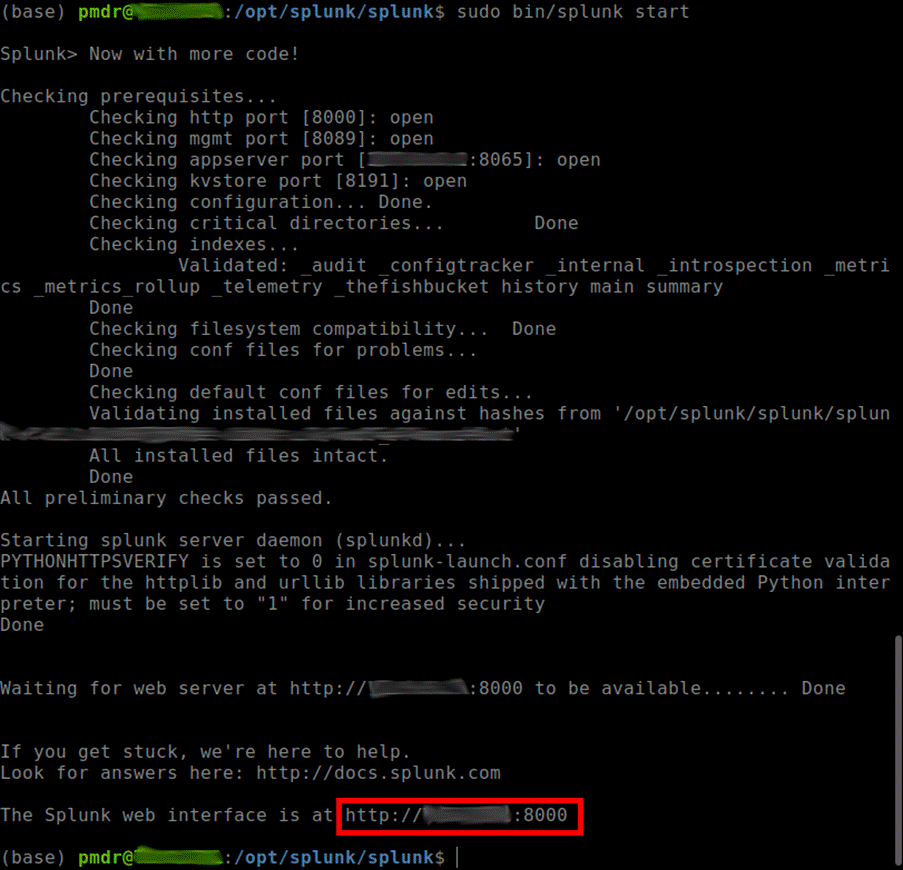
3. Faça login com o usuário e senha cadastrados durante a instalação do Splunk

Instalando o DSDL
Precisamos agora instalar o DSDL e seus pré-requisitos:
- Machine Learning Toolkit (MLTK)
- Python for Scientific Computing
Assim, no Splunk, clique em “+ Find More Apps” como indicado na Figura 8 e procure pelos nomes dos aplicativos Python for Scientific Computing, MLTK e DSDL, conforme indicado na Figura 9, e os instale conforme indicado nas Figuras 10, 11 e 12.

Configurando o Container
Como dito, o DSDL funciona em um container. Assim, vejamos agora como configurá-lo.
Primeiramente, precisamos instalar o docker na máquina em que o container será executado, conforme as instruções em https://docs.docker.com/get-docker/.
Após instalar o docker, siga os passos a seguir:
- Execute o comando abaixo para fazer o download da imagem que será utilizada pelo container.
sudo docker pull phdrieger/mltk-container-golden-image-cpu:5.0.0

2. Adicione permissões ao docker com os comandos
a. Adicione um grupo para o docker:
sudo groupadd docker
b. Defina as permissões:
sudo usermod -aG docker $USER
c. Faça logout e depois login no sistema ou uso o comando
newgrp docker
d. Verifique se é possível executar comandos sem sudo rodando
docker run hello-world
Em caso de dúvida ou para obter informações mais detalhadas acesse https://docs.docker.com/engine/install/linux-postinstall/
3. Por fim, inicie o container com o comando
docker run phdrieger/mltk-container-golden-image-cpu:5.0.0
Com o container rodando corretamente, agora basta terminar o setup dentro do DSDL. Para isso siga os passos a seguir:
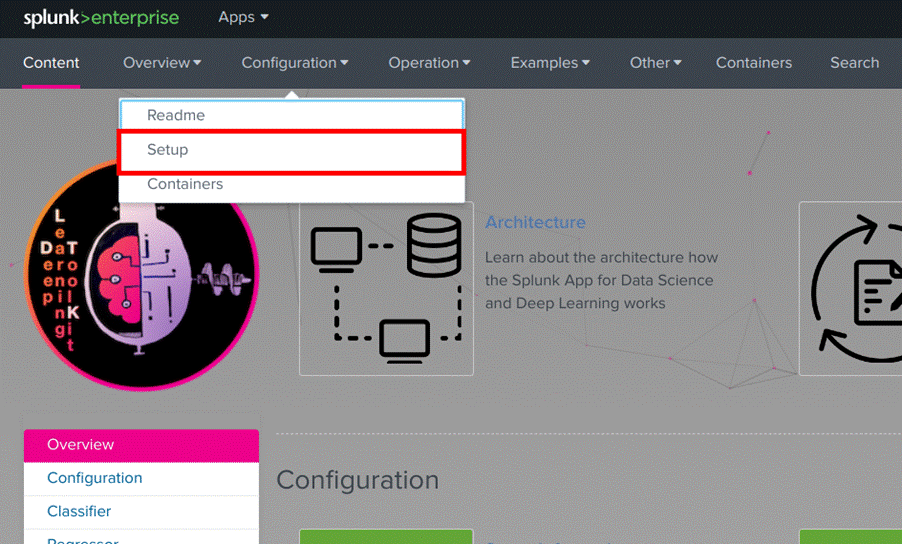
4. Na tela inicial do App DSDL, vá em “Configurações->Setup” como mostrado na Figura 14.
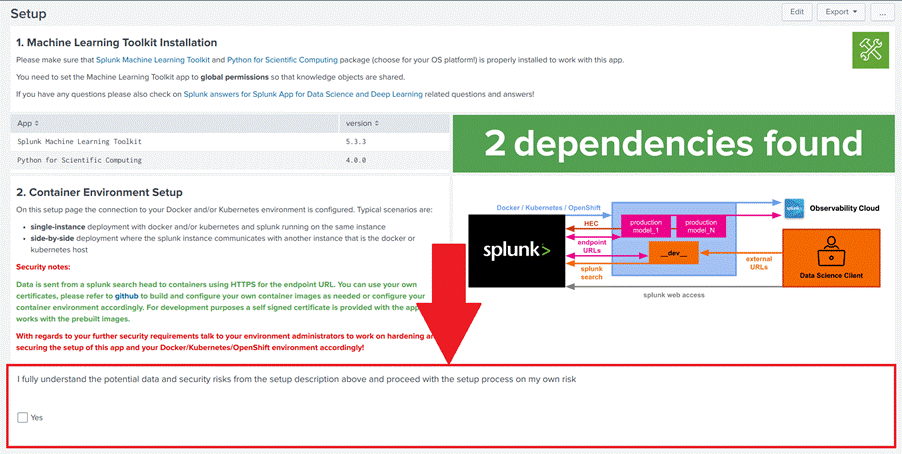
5. Marque a caixa concordando com o risco, como nas Figuras 15 e 16.

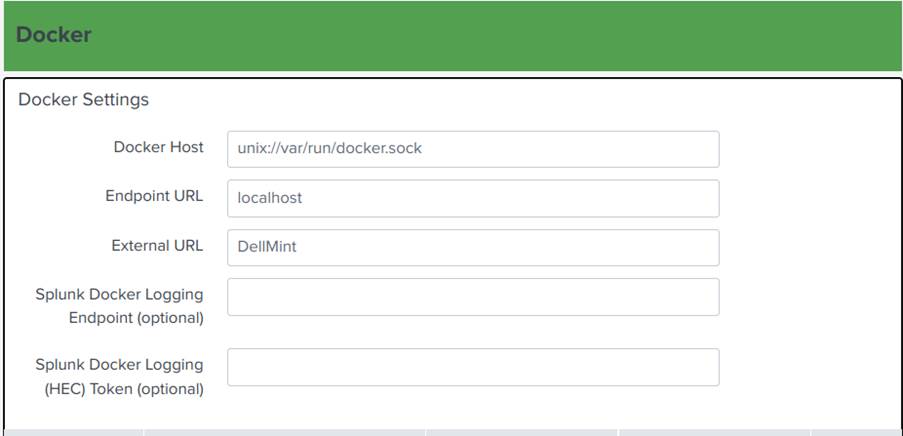
6. Por fim preencha os campos da Figura 17 como descrito a seguir:
a. Docker Host: unix://var/run/docker.sock
b. Endpoint URL: localhost
c. External URL: hostname (pode ser encontrado rodando o comando $hostname no terminal)
7. Clique em Test & Save no final da página.
Criando Modelos de Detecção usando Machine Learning
Finalmente, temos tudo pronto para implementar modelos de detecção usando machine learning no Splunk. Vejamos então agora como fazê-lo. Para isso, precisaremos de dados e de um algoritmo de detecção.
Obtenção de Dados
Neste blog post, implementamos um modelo de machine learning para detectar anomalias em logs de firewall. Utilizamos uma base de dados com logs de firewall disponível no Splunk. Assim, vamos primeiro encontrar essa base e nos certificar que ela pode ser acessada pelo DSDL seguindo os passos a seguir:
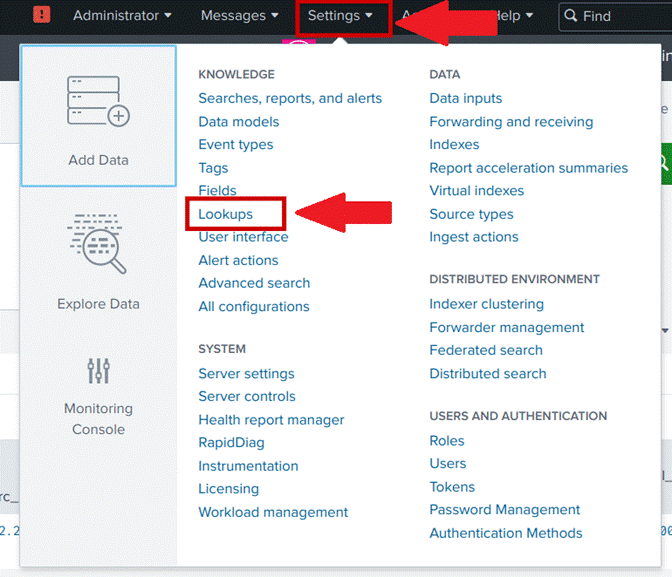
- Clique em settings, na barra superior do Splunk;
- Clique em Lookups, conforme a Figura 18;
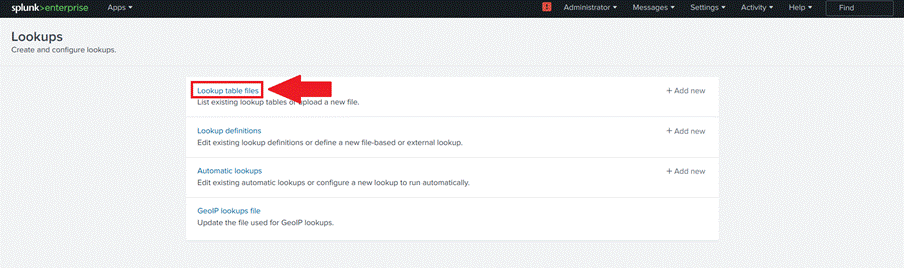
- Clique em Lookup table files, como mostra a figura 19;
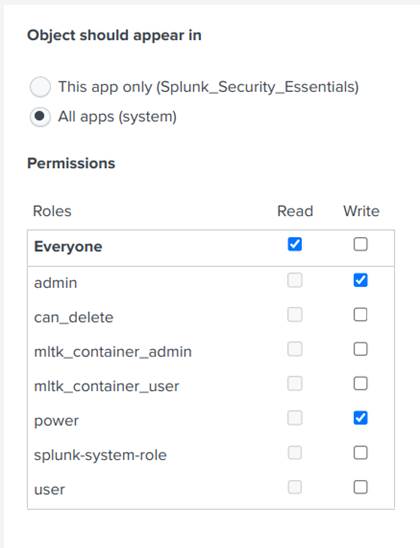
- Pesquise por firewall_traffic e clique em Permissions, conforme a Figura 20;
- Por fim, certifique-se de que as configurações de permissão estão iguais às da Figura 21.

Em seguida, vamos aprender a fazer buscas por esses dados, analisando os seus atributos, selecionando features e convertendo variáveis categóricas em variáveis numéricas:
- Vá para guia de search do Splunk, lá será feita toda a manipulação e visualização dos dados, como indicado na Figura 22. Todos os comandos que iremos mostrar a seguir devem ser usados em conjunto, para adicionar comandos em uma nova linha basta pressionar Shift+Enter e colar o comando na linha criada.
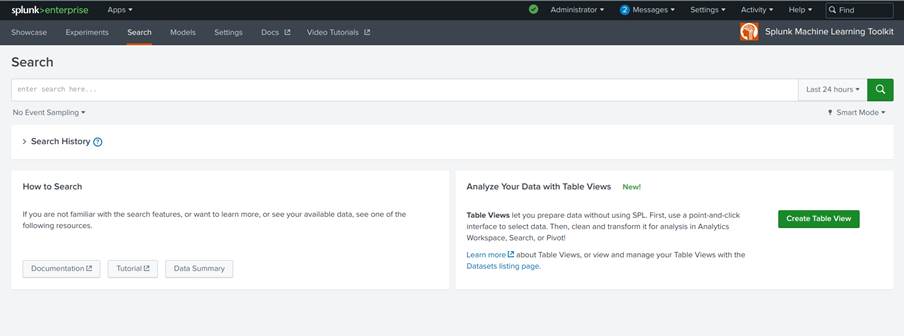
Figura 22. Tela de searches do DSDL - Para uma primeira visualização dos dados insira a query:
| from inputlookup:firewall_traffic.csv
Esse comando irá retornar todos os dados do csv sem nenhum tratamento, como ilustrado na Figura 23.
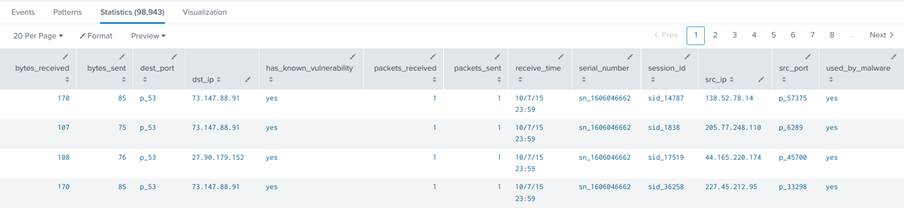
3. Em seguida, para que seja retornado só os campos que desejamos, insira a query:
|fields + bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware
Ela retornará apenas os campos descritos depois do caractere “+”
4. Dividiremos agora o dataset em conjunto de treino e teste, para isso insira a query:
| sample partitions=10 seed=23 | where partition_number < 7
O comando sample divide o dataset em um número específico de partições com base em uma semente. Nesse caso, criamos 10 partições usando a semente 23. Na sequência, utilizamos o comando where para retornar apenas as 7 primeiras partições criadas. Dessa forma dividimos o dataset em conjunto de treino e teste utilizando a proporção 70% treino e 30% teste.
5. O campo used_by_malware será usado pelo modelo, contudo ele é categórico e precisa ser convertido para valores numéricos. Para esse ajuste, use as querys:
| eval used_by_malware_yes = case(used_by_malware == "no", 0, used_by_malware == "yes", 1) | eval used_by_malware_no = case(used_by_malware == "no", 1, used_by_malware == "yes", 0)
Esses comandos convertem o campo categórico em duas novas variáveis numéricas com a mesma informação.
6. Possivelmente veremos alguns campos sem valor no dataset. Para lidar com eles, adicionar o comando:
| fillnull value=0
Ele irá preencher os valores nulos com o valor 0.
7. Por fim, para gerar uma tabela contendo apenas os valores dos atributos que nos interessam, acrescente o comando:
| table bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware_yes, used_by_malware_no
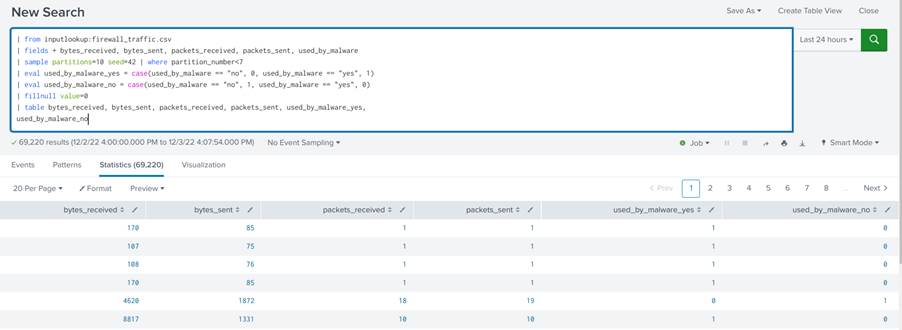
A query completa, composta pela junção das querys mostradas anteriormente, fica com a seguinte forma:
| from inputlookup:firewall_traffic.csv |fields + bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware | sample partitions=10 seed=23 | where partition_number < 7 | eval used_by_malware_yes = case(used_by_malware == "no", 0, used_by_malware == "yes", 1) | eval used_by_malware_no = case(used_by_malware == "no", 1, used_by_malware == "yes", 0) | fillnull value=0 | table bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware_yes, used_by_malware_no
A query completa deve resultar em uma tabela com os dados pré-processados como mostrado na Figura 24.
Modelo de detecção
A seguir utilizaremos o Splunk com o módulo DSDL para construir um modelo de um autoencoder, algoritmo de machine learning, bastante usado para detectar anomalias.
Autoencoders são uma estrutura de redes neurais cujo funcionamento se baseia em comprimir os dados de entrada, gerando uma representação latente de menor dimensão, e em seguida descomprimi-los reconstruindo-os. O modelo aprende a diminuir o erro de reconstrução entre os dados de entrada e saída. Ao treinar esse tipo de arquitetura com apenas dados benignos de redes ou sistemas, ela irá produzir pequenos erros de reconstrução ao processar dados benignos e grandes erros de reconstrução ao processar dados maliciosos, uma vez que estes não foram utilizados no treinamento. Para mais informações, sugerimos a leitura do quarto post da série citada anteriormente: Detecção de Intrusão usando Autoencoders.
Implementando o Modelo
Com os dados em mãos, vamos agora implementar o modelo de um autoencoder. Os modelos usados no DSDL são feitos em linguagem Python por meio de um Jupyter Notebook. Para acessar os notebooks usados no Toolkit, volte para a página inicial do DSDL e acesse a opção Containers. Selecione a Golden Image CPU, clique em start, e depois em JUPYTER LAB, conforme indicado nas Figuras 25 e 26:
Caso seja pedida uma senha para logar nos notebooks utilize a senha padrão: Splunk4DeepLearning
Dentro da aba JupyterLab abra a pasta notebooks, e duplique o arquivo “autoencoder_tutorial.ipynb”, para isso selecione o arquivo, clique nele com o botão direito do mouse e em seguida clique em duplicar. Agora, renomeie a cópia com o nome que quiser, escolhemos “SideChannel_model”, conforme ilustrado nas Figuras 27 e 28.
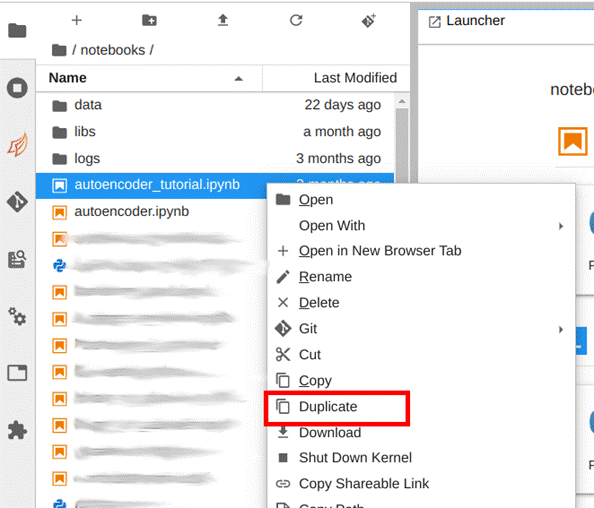
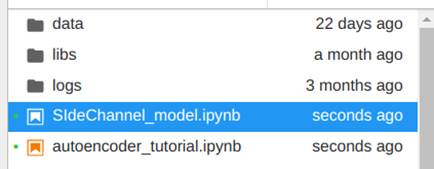
Esse arquivo contém um tutorial completo de como criar um novo modelo no DSDL. Basicamente já temos um autoencoder pronto. A ideia agora é entender como a estrutura do código funciona para que possamos alterá-lo como quisermos. Mas, antes disso, para podermos testar o código precisamos que os dados da nossa search estejam disponíveis para o notebook. Assim, para enviá-los para o notebook, execute a search feita para exibição de dados no tópico anterior e adicionar o comando fit da seguinte forma:
| from inputlookup:firewall_traffic.csv |fields + bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware | sample partitions=10 seed=23 | where partition_number < 7 | eval used_by_malware_yes = case(used_by_malware == "no", 0, used_by_malware == "yes", 1) | eval used_by_malware_no = case(used_by_malware == "no", 1, used_by_malware == "yes", 0) | fillnull value=0 | table bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware_yes, used_by_malware_no | fit MLTKContainer mode=stage algo=SideChannel_model bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware_yes, used_by_malware_no into app:SC_Autoencoder
Essa chamada do comando de fit do Splunk indica que o Splunk deve enviar os dados obtidos com a search para o algoritmo SideChannel_model no container usando o modo stage. O comando segue com a lista de campos dos dados que serão enviados para o modelo e o nome da instância do modelo que salvaremos, nesse caso SC_Autoencoder. O modo stage (mode=stage) significa que os dados serão enviados para o ambiente de desenvolvimento, onde está nosso notebook, dessa forma poderemos usar os dados para treinar o modelo. Ao adicionar o comando fit na search, serão criados dois arquivos no diretório notebook/data do JupyterLab, um arquivo json e um arquivo csv, o primeiro contém as informações de configurações enviadas para o modelo, e o segundo os dados.
Vamos agora entender o funcionamento de cada célula do código presente no notebook do autoencoder:
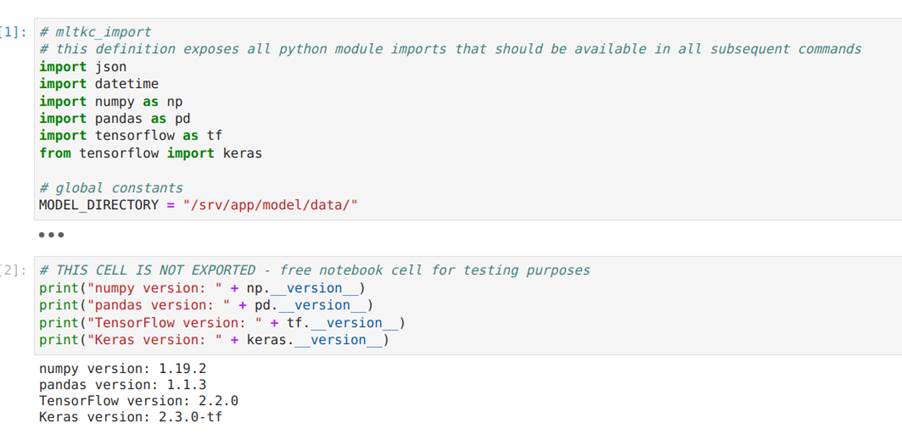
A Figura 29 apresenta a primeira célula de código do notebook, que contém os imports das bibliotecas usadas pelo código em Python e a definição do diretório onde o modelo será salvo após o seu treinamento. Como apenas bibliotecas instaladas no container podem ser usadas, para usar outras bibliotecas pode ser necessário construir um novo container com as novas dependências.
A segunda célula, também na Figura 29, serve apenas para mostrar a versão de cada módulo e não é exportada para o código final.
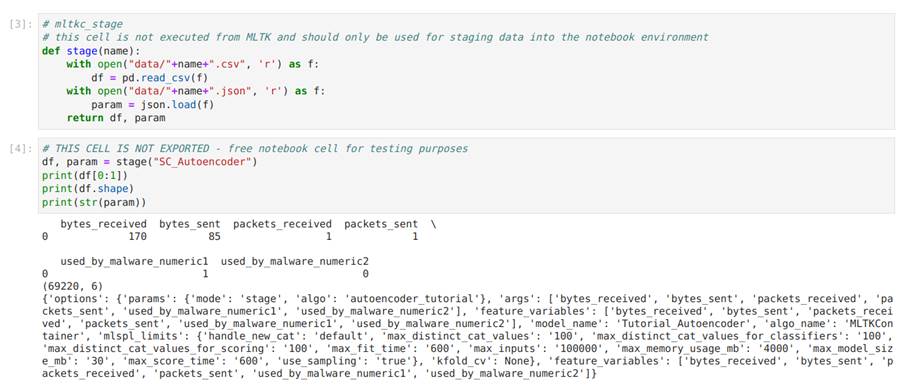
A Figura 30 apresenta duas células de código que são muito importantes para a utilização do notebook. A função stage serve para ler os dados e os parâmetros que foram enviados para a pasta data. Repare que os dados vêm no formato de csv e os parâmetros são lidos como um objeto json. Na imagem vemos a implementação da função e na sequência a sua execução.
A Figura 30 ilustra a célula de código responsável por definir a função init para a inicialização do modelo do autoencoder, bem como a célula de código em que a função init é chamada. Conforme apresentado, a função init recebe como entrada um dataframe com parâmetros de configuração e retorna como saída o modelo declarado. Neste exemplo, o modelo é criado usando a biblioteca Keras. Na Figura 31, modificamos a função init adicionando uma camada densa na arquitetura do autoencoder apenas para mostrar como é simples alterar o código.
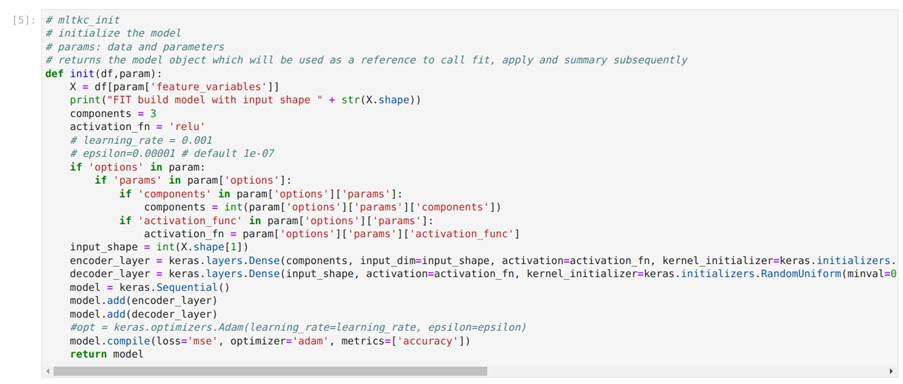
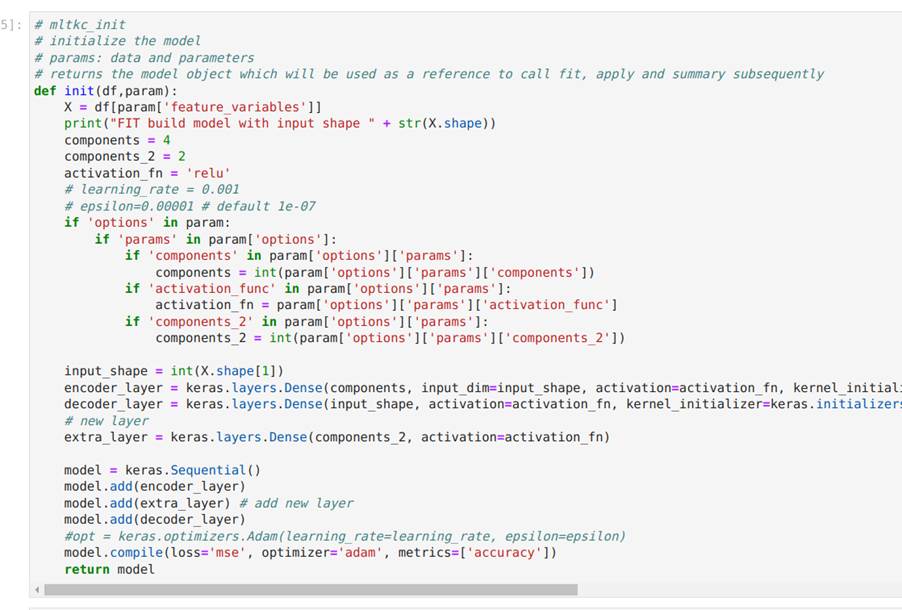
Na Figura 33, executamos a função init para instanciar um modelo e, na sequência, utilizamos o método summary presente nos modelos gerados pelo pacote Keras para mostrar a arquitetura do modelo criado.
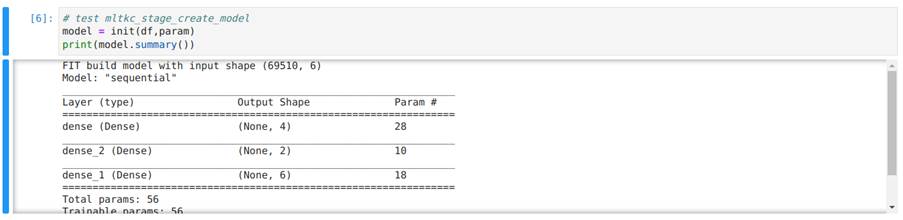
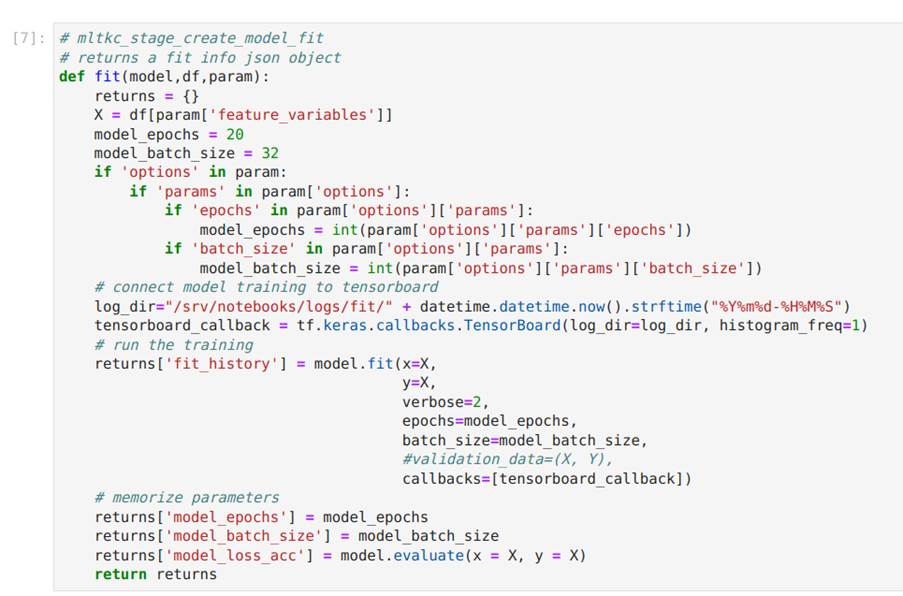
Na Figura 33, mostramos a implementação da função fit que recebe, como entrada, o modelo, um dataset e parâmetros de configuração, e retorna o modelo treinado juntamente com algumas outras informações. É importante não alterar as informações retornadas para garantir que o modelo funcione corretamente.
Na Figura 34, treinamos o modelo chamando a função fit.
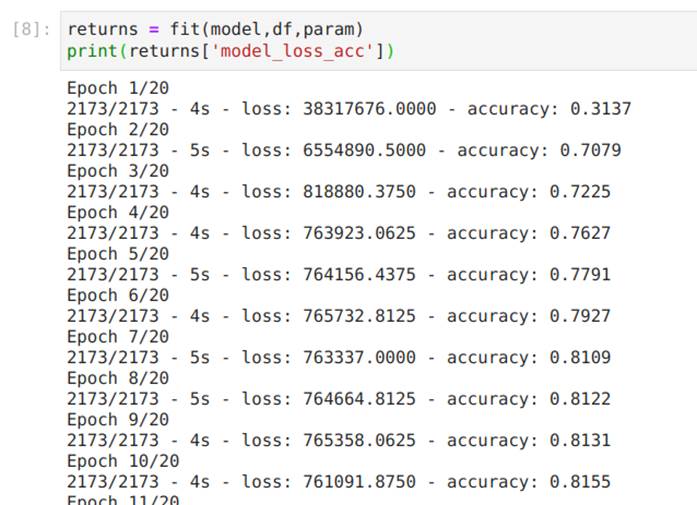
Na Figura 36, apresentamos a função apply do modelo, que recebe o modelo e um dataframe com parâmetros como entrada, e retorna um dataframe com as saídas do modelo:

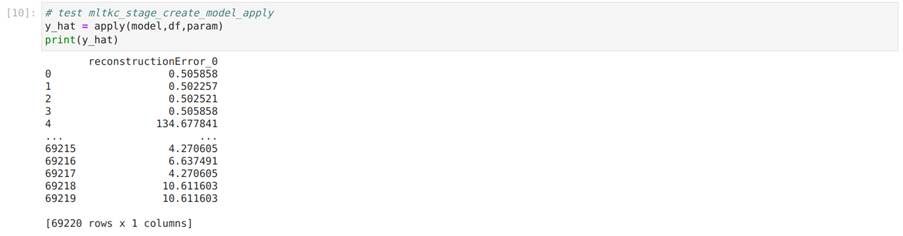
A fim de detectar anomalias, alteramos o código dessa célula comentando as 3 linhas acima do comando return e adicionando um pequeno trecho de código que calcula o erro quadrático médio entre a entrada e saída do autoencoder. Assim, passamos a ter um único valor que representa o erro total de reconstrução do autoencoder e que representa um indicativo de quão anômalo um dado é. O código adicionado é descrito abaixo e na Figura 37:
reconstruction_error = tf.keras.losses.mean_squared_error(X, reconstruction).numpy()
y_hat = pd.concat([pd.DataFrame(reconstruction_error).add_prefix("reconstructionError_")], axis=1)

Na Figura 38, testamos a função apply utilizando os dados:
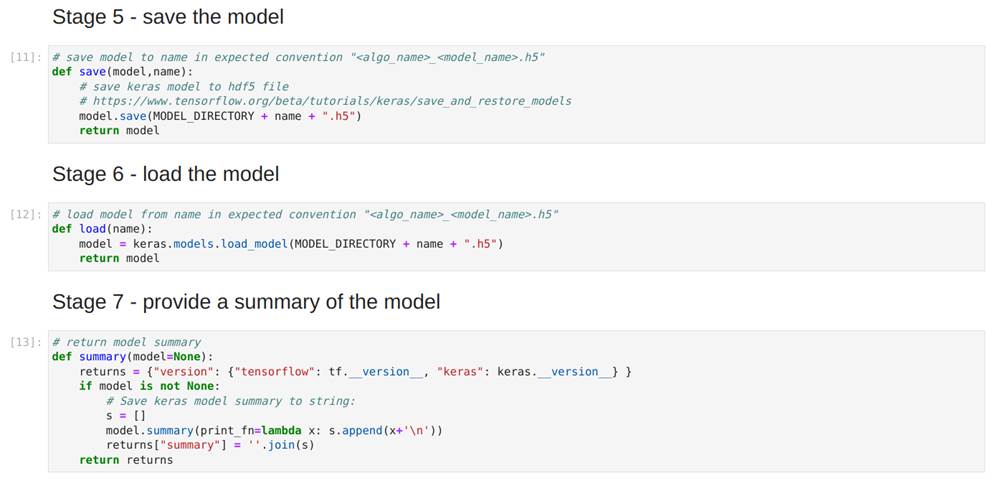
Por fim, exibimos na Figura 39 as funções save, load e summary, que salvam o modelo, carregam-no para o ambiente e retornam uma string descritiva do modelo, respectivamente:
O notebook contendo todas as alterações pode ser encontrado em: https://github.com/tempestsecurity/splunk_dsdl_tutorial
Usando o modelo diretamente com searches no Splunk:
Além de treinar e aplicar um modelo de detecção através do Jupyter notebook, também podemos treiná-lo e aplicá-lo realizando searches diretamente no Splunk. Para fazer isso, precisamos primeiramente entender como os notebooks interagem com as searches.
Podemos incluir nas searches do Splunk realizadas a partir da tela de search do DSDL dois comandos: fit e apply. Esses comandos chamam, em uma ordem específica, funções de um script python que é salvo no container automaticamente todas as vezes que o código do Jupyter notebook é salvo. Temos 6 funções principais dentro do código de um modelo que serão usadas no script python:
- init
- fit
- apply
- save
- load
- summary
Assim, ao realizar uma search utilizando a função fit do Splunk (a mesma usada nas querys mostradas anteriormente), cujo objetivo principal é treinar o modelo, é executado um script que utiliza as funções do modelo, explicadas na seção anterior com o Jupyter notebook, de acordo com o diagrama da Figura 40.
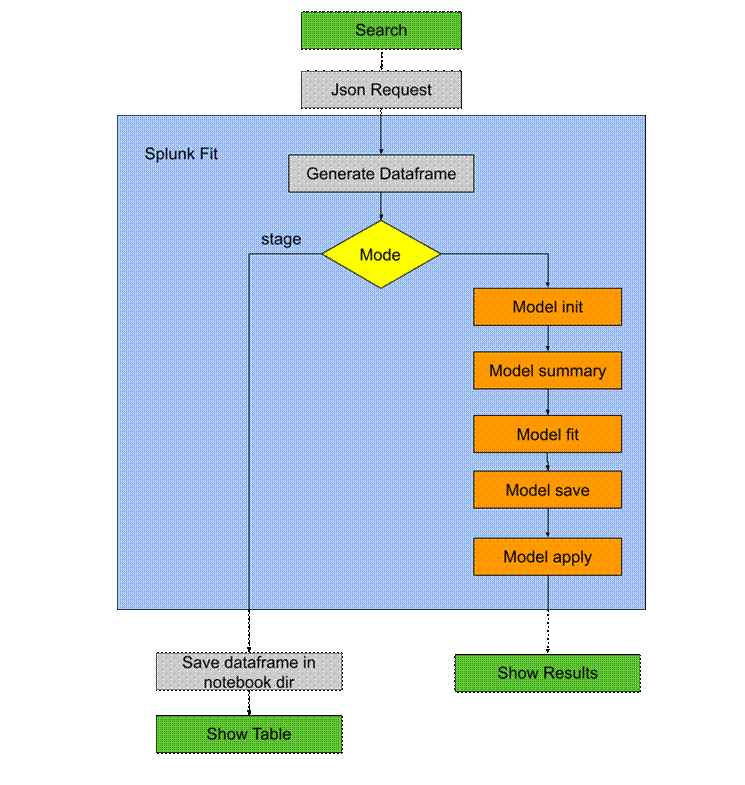
Após chamar a função de treinamento, para aplicar o modelo treinado aos dados, usamos a função apply do Splunk, que, por sua vez, chama as funções explicadas com Jupyter notebook conforme a sequência exibida na Figura 41.
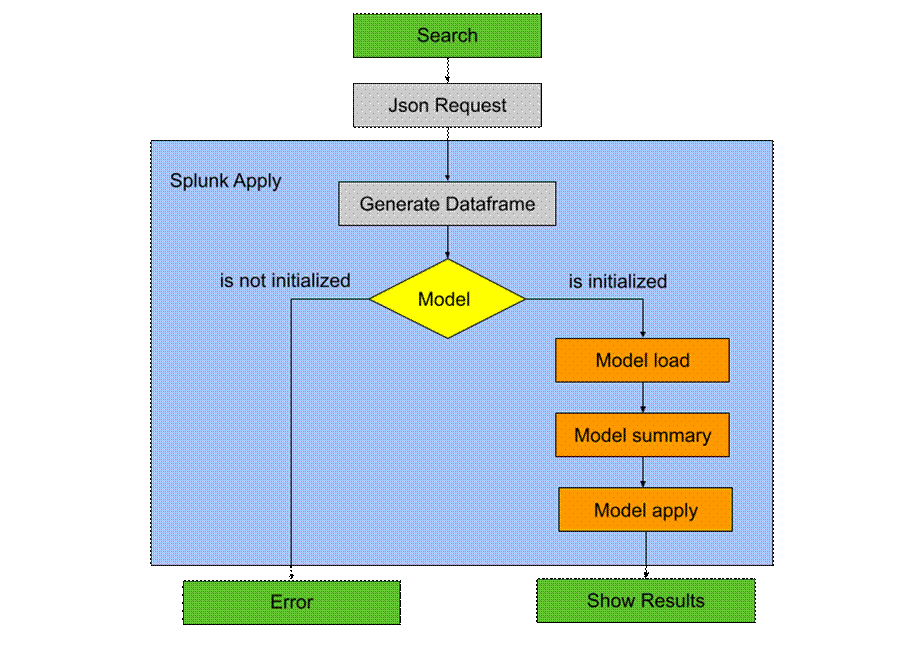
Com isso, em resumo, para treinar e aplicar o modelo através das searches do Splunk basta realizar 3 passos, o treinamento com a função fit do Splunk, a inferência com a função apply do Splunk, e a definição de uma regra de detecção:
- Treinamento
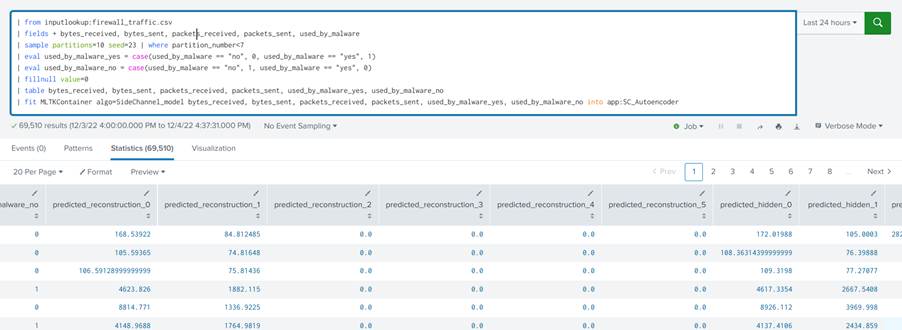
Para treinar o modelo diretamente por meio da search basta utilizar o comando “fit” na query, mas dessa vez sem passar o argumento mode=stage. O comando “fit” sem a opção de stage irá executar as funções presentes no script python do modelo e salvar a instância do modelo com o nome passado após “app:”. A sequência das funções pode ser vista no diagrama mostrado anteriormente. Treinando o modelo por meio da search, temos:
Query completa:
| from inputlookup:firewall_traffic.csv | fields + bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware | sample partitions=10 seed=23 | where partition_number<7 | eval used_by_malware_yes = case(used_by_malware == "no", 0, used_by_malware == "yes", 1) | eval used_by_malware_no = case(used_by_malware == "no", 1, used_by_malware == "yes", 0) | fillnull value=0 | table bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware_yes, used_by_malware_no | fit MLTKContainer algo=SideChannel_model bytes_received, bytes_sent, packets_received, packets_sent, used_by_malware_yes, used_by_malware_no into app:SC_Autoencoder
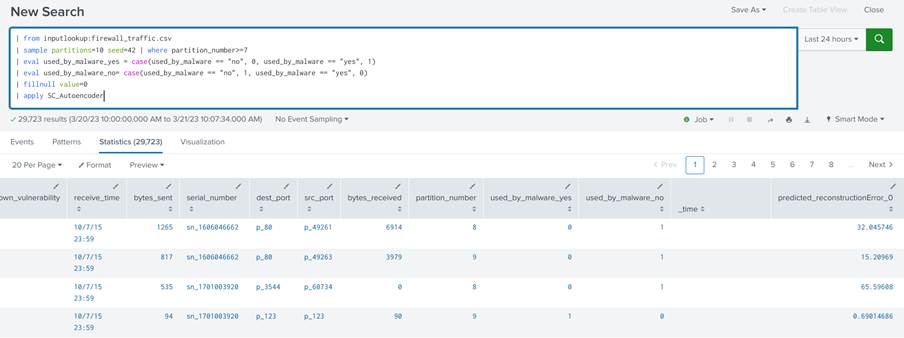
2. Inferência
Uma vez com o modelo treinado, basta que ele seja aplicado nos dados de teste. Para isso utilizamos o comando apply do Splunk na query e passamos como único argumento o nome da instância treinada do modelo, SC_Autoencoder:
| from inputlookup:firewall_traffic.csv | sample partitions=10 seed=42 | where partition_number>=7 | eval used_by_malware_yes = case(used_by_malware == "no", 0, used_by_malware == "yes", 1) | eval used_by_malware_no= case(used_by_malware == "no", 1, used_by_malware == "yes", 0) | fillnull value=0 | apply SC_Autoencoder
Na query acima carregamos os dados, pegamos apenas as partições que utilizamos para teste, fazemos o pré processamento e por fim aplicamos o modelo:
Na saída teremos os dados de entrada concatenados com seus respectivos valores preditos.
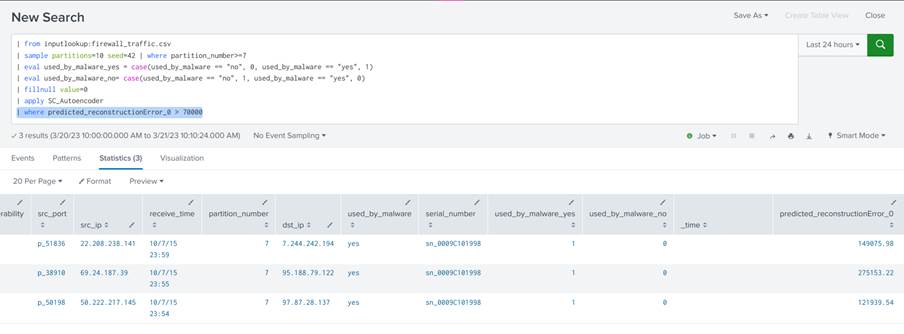
3. Regra de detecção
Por fim, para transformar os resultados em uma regra de detecção basta adicionar o comando where a query e especificar um limiar para o campo contendo os erros de reconstrução:
| where predicted_reconstructionError_0 > 70000
Algumas dicas importantes para a elaboração de modelos mais sofisticados:
- Caso a função apply do seu modelo retorne dados temporais eles devem ser ordenados de maneira decrescente;
- Os modelos chamados no Splunk são executados a partir da raiz do JupyterLab, por isso caso queira adicionar módulos customizados escritos em Python eles devem ser colocados lá;
- Como a função fit do Splunk também chama o apply ela é ideal para a realização de treinamentos online;
- É possível criar um container customizado a partir do repositório padrão do MLTK container disponível no github.
Conclusão
Nesse post, mostramos como instalar e usar a ferramenta DSDL para a implementação, treinamento e uso de modelos de machine learning para detecção de anomalias no Splunk, tópico de fundamental importância para o deployment de modelos de detecção baseados em aprendizagem de máquina.
Referências
[1] Liao, Hung-Jen, et al. “Intrusion detection system: A comprehensive review.” Journal of Network and Computer Applications 36.1 (2013): 16-24.
[2] Chandola, Varun, Arindam Banerjee, and Vipin Kumar. “Anomaly detection: A survey.” ACM computing surveys (CSUR) 41.3 (2009): 1-58.
[3] A. L. Buczak and E. Guven, “A Survey of Data Mining and Machine Learning Methods for Cyber Security Intrusion Detection,” in IEEE Communications Surveys & Tutorials, vol. 18, no. 2, pp. 1153-1176, Secondquarter 2016, doi: 10.1109/COMST.2015.2494502.
[4]Chalapathy, Raghavendra, and Sanjay Chawla. “Deep learning for anomaly detection: A survey.” arXiv preprint arXiv:1901.03407 (2019).
[5] Splunk App for Data Science and Deep Learning https://splunkbase.splunk.com/app/4607