Aqueles que trabalham com ferramentas de prevenção a vazamento de dados provavelmente conhecem o produto Symantec DLP, reconhecidamente uma das melhores ferramentas de prevenção a vazamento de dados do mercado.
A ferrramenta possui alguns módulos de atuação, o mais comum deles e também um dos mais requisitados é o “DLP Endpoint”, que concentra diversas funções de atuação para prevenção a vazamento de dados.
Este artigo técnico descreve a resolução de problemas aplicados ao módulo de Endpoint, tentando assim explicar a lógica de atuação do Endpoint Prevent como um todo, desde o agente aplicado nas estações de trabalho, até os servidores responsáveis por controle e comunicação, além de englobar rotas e até o nível técnico da aplicação.
A Symantec é uma das empresas com produtos voltados a segurança de dados. Um destes serviços oferecidos incluem o Symantec DLP que promete monitorar comportamentos em aplicativos suspeitos instalados pelo usuário, interromper o roubo de dados, identificar e impedir que aplicativos inválidos obtenham dados confidenciais e restringir transferências de dados que não estejam em conformidade e de dados pessoais de proteção verificável (de acordo com o próprio site da empresa). Ao analisar o Symantec DLP com um único Detection (Endpoint Server) é possível entender o status atual de sua saúde do produto, como será demonstrado a seguir.
Primeiramente, através da conferência do status de cada monitor e do Enforce (servidor responsável pela administração dos outros monitores), foi possível observar que o ultimo possui mais de 72 incidentes em fila e o Endpoint Prevent está com o status em “iniciando”, sem pleno funcionamento. A partir desta análise inicial e do aprofundamento nos eventos e logs sugeridos, obteve-se os seguintes resultados:
1. Enforce e o serviço “Symantec DLP Incident Persister”, responsável pelas gravações dos arquivos .IDC na base de dados, não fazendo sua função, por conta de não ter o nível de processamento necessário.
2. Endpoint Prevent apontava um erro no serviço responsável pela entrega dos incidentes para a base de dados. O monitor por sua vez não estava recebendo novos incidentes.
Com isto foi analisado os alertas, bem como os logs específicos, permitindo a identificação de problemas com status críticos e não críticos, sendo eles:
- Evento 1101 — Endpoint Agregator não consegue iniciar;
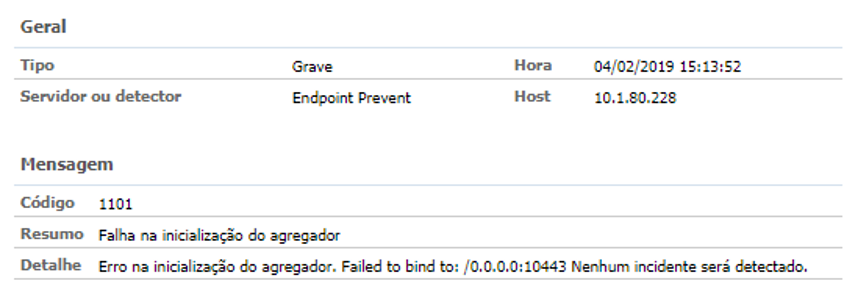
2. Evento 3900 — Endpoint Agregator — Erro interno de Comunicação;
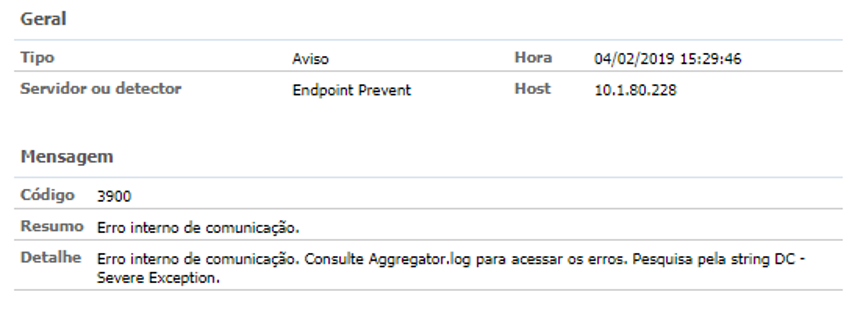
3. Evento 1800 — Incident Persister não consegue processar o incidente X;
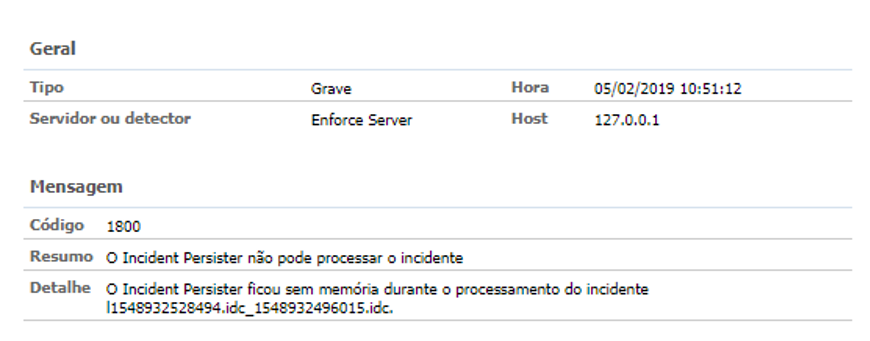
4. Evento 2317 (não crítico) — Enforce Notificação de e-mail não enviada;
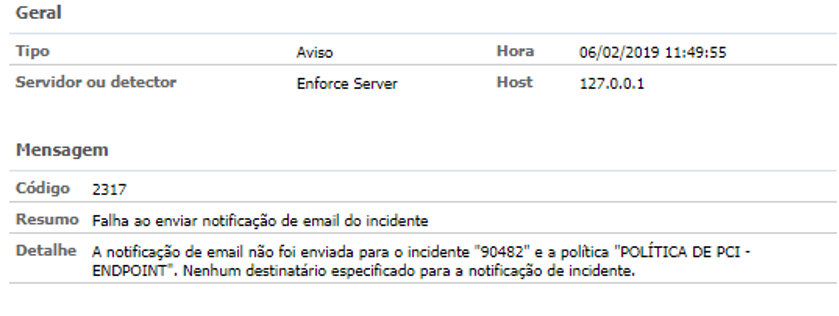
Identificados tais eventos, foi analisado se o tráfego foi de alguma forma afetado; seja pela parada de entrega dos incidentes ou pela queda de algum serviço, entendendo-se que o serviço do Endpoint Prevent não estava em pleno funcionamento. A seguir a imagem do tráfego na semana da análise, que demonstra queda entre o dia 31 de janeiro ao dia 4 de fevereiro por conta do enfileiramento dos incidentes não processados parados dentro do Enforce.

Com estas informações em mãos, também foi analisado a Base de Dados Oracle em algumas tabelas específicas, como por exemplo, a LOB_TABLESAPACE, responsável por guardar os incidentes. Nesta análise, obtivemos um resultado plenamente satisfatório, demonstrando que a saúde das tabelas estão em 100%, conforme demonstrado na imagem abaixo.
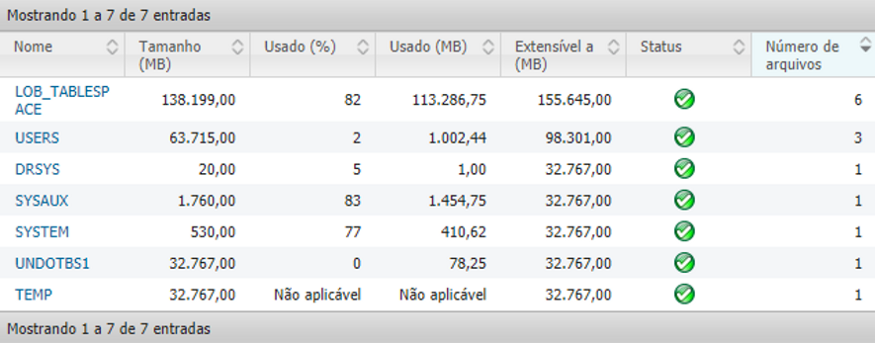
Para que funcionem sem problemas, as tabelas devem ser configuradas pelo responsável do Banco de dados, para que assim, caso seja completamente preenchidas, serem criadas e preenchidas novas tabelas.
Possíveis Causas e ações
As causas dos problemas apontados na análise estão listadas e descritas abaixo. Alguns destes problemas são interligados, como o nível de processamento no Enforce e Incidentes em fila.
Incidentes em fila
Os incidentes em fila ocorreram devido ao tamanho dos arquivos .idc (incidentes) dentro da pasta temporária onde ficam até serem processadas pelo serviço responsável pela entrega à base de dados. Com o serviço sem nível de processamento necessário, ele entrava em um ciclo de processamento e queda. Como ele tentava carregar o incidente na base e não conseguia, o time-out era ativado e assim após alguns segundos era gerado outra tentativa, que resultou novamente em uma falha. Com isso os incidentes maiores que 300mb ficavam na pasta temporária sem serem entregues, gerando fila.
Possível ação: Entregar mais processamento a JVM responsável por subir e administrar o serviço, dessa forma terá a performance necessária para enviar a base de dados.
Como ação tomada para resolução do problema “incidentes em fila”, foi feita uma modificação no ambiente envolto ao processamento do servidor, pedindo mais 8gb de ram, ficando assim 16gb no total. Além disso, os arquivos responsáveis pela locação de processamento para a JVM, da qual administra os serviços do DLP, foram modificados para que consigam entregar o máximo necessário de processamento à JVM, deste modo os incidentes são entregues à base de dados. A modificação foi efetuada no path C:\Program Files\Symantec\Data Loss Prevention\Enforce Server\15.1\Protect\services, modificando os arquivos SymantecDLPDetectionServerController.conf,SymantecDLPIncidentPersister.conf, e SymantecDLPManager.conf. Observe nas imagens os locais específicos dos arquivos o qual foram alterados.
Nas seguintes áreas:
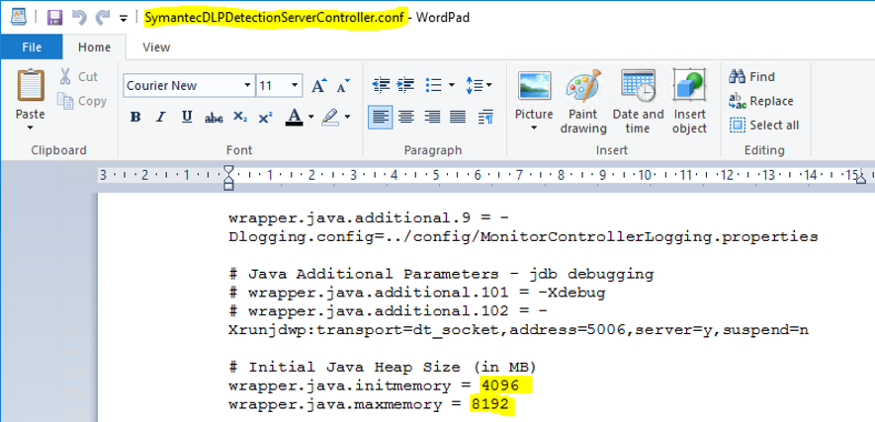
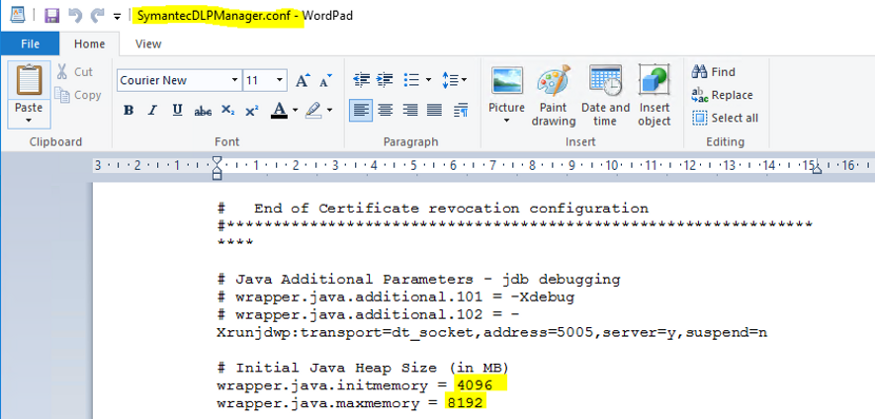
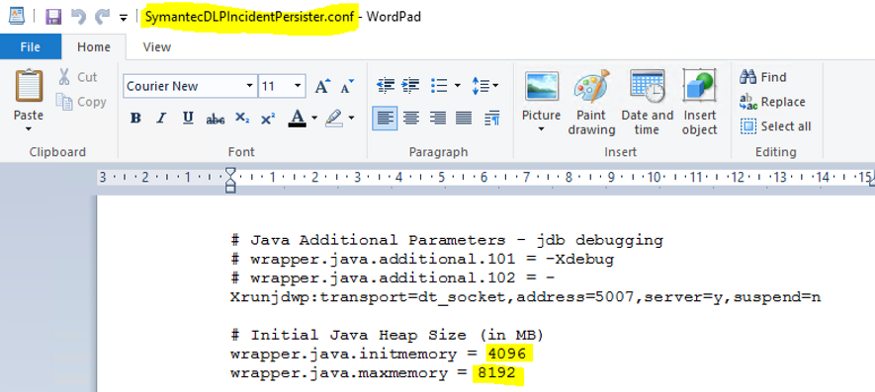
Com essas alterações foi possível fazer com que os incidentes fossem processados e a fila zerada, desde os incidentes com 300mb até os incidentes de 1gb ou mais.
Resultado da ação;
· Fila zerada;

· Uso de disco do servidor de 80–85% foi para 50–58%;
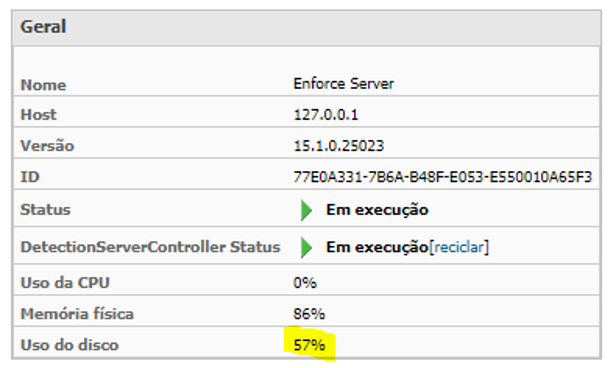
· Entrega de todos os .idc para a base de dados, tanto os de 300mb quanto os acima de 1gb;
Ação tomada:
Endpoint sem pleno funcionamento
Com a falha do Agregator, que é responsável pela conferência e a estabilização da portas de comunicação, o Endpoint não consegue receber nem entregar os incidentes, pois não estava conseguindo fazer a conferência do FQDN (nome do domínio absoluto). Foi observado também que por padrão a Empresa X está ativando em todos os servidores o IPV6. Além disso, por algum motivo ainda não justificado pela Symantec, o serviço do Detection Endpoint Prevent não consegue fazer a conferência do FQDN nem subir as portas responsáveis pelo tráfego pelo IPV6.
Possível ação: Desativar o IPV6 e deixar somente o IPV4 no servidor até um parecer da Symantec. Também é recomendado fazer a configuração do arquivo de Communication para que o Bind seja executado do modo correto, pois o arquivo está diferente do usual.
Observação: Essa possível ação resultará na correção dos dois problemas, este e “Agregator do servidor endpoint não inicializando”.
Problema no Agregator
Para a solução do mal funcionamento do Agregator foi feita a modificação do arquivo “Communication” dentro do servidor Endpoint Prevent para que o Bind seja executado pelo FQDN (TesteempresaX.com.br). Também foi desativado o IPV6 do servidor e mantido o IPV4. A modificação foi feita no seguinte arquivo no seguinte local C:\Program Files\Symantec\Data Loss Prevention\Detection Server\15.1\Protect\config, no arquivo Communication.
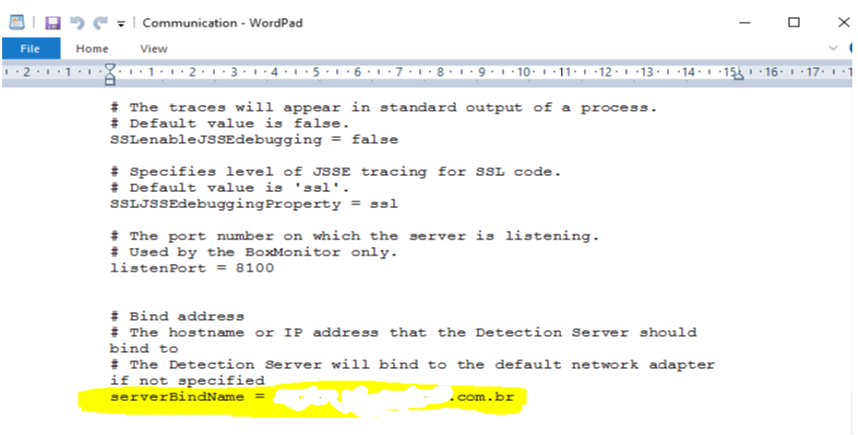
Através deste processo foi possível reiniciar os serviços do Endpoint Prevent e a comunicação voltou a funcionar normalmente, bem como o monitor a entregar e receber os incidentes.
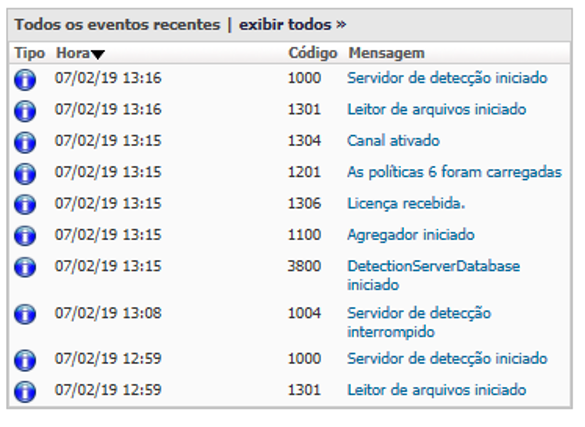
Resultado da ação:
· Serviço do Endpoint Prevent funcionando normalmente;
· Agregrator mantendo a conferência sem problemas;
Incident Persister não processando incidentes
Os incidentes vindos do Endpoint prevent eram direcionados para uma pasta temporária do Enforce aguardando processamento pelo Serviço Persister. No entanto o serviço não conseguiu processar qualquer incidente maior que 300mb por conta do seu “time-out” de processamento e ram necessária para tal.
Possível Ação: Alterar os arquivos responsáveis pelo apontamento de limite de processamento dado a JVM que controla os serviços, sendo assim, respeitando o limite de memória ram do servidor, que era de 8gb. Com essa mudança a JVM alocará mais memória para o processamento dos incidentes tidos como grandes (maiores que 300mb)
Disco do Servidor Enforce com mais de 80% de uso.
Assim como os incidentes de 300mb, neste caso a JVM era forçada a processar os incidentes e ao não conseguir dava o “time-out” e finalizava o processo, para segundos depois iniciar novamente, forçando o processamento do servidor. Com a possível ação sugerido no item “Incidentes em fila” a seguir, seria possível diminuir o processamento, pois os incidentes de até 800mb serão processados; porém apenas aqueles com peso inferior a 1gb.
Possível ação: Aumentar a memória ram do servidor de 8gb para 16gb e efetuar a configuração dos arquivos responsáveis pela JVM e divisão de processamento para que consigam utilizar o máximo de processamento necessário sem entregar um “time-out”.
Recomendações de melhorias para o ambiente
Ponto 1 — Para que o ambiente funcione sem que um único monitor se sobrecarregue com todas as funções, seria de muito interesse e beleza técnica que mais Detections fossem adicionados ao ambiente, como por exemplo, o Mail Prevent, o qual poderia assumir toda a responsabilidade de analisar o tráfego e arquivos que naveguem através de SMTP. Assim seria tirado um grande nível de processamento dos agentes de Endpoint, fazendo com que as políticas atualmente aplicadas para fazer inspeção SMTP, foquem em outros processos de informações.
Para que seja retido os e-mails e não excluídos em alguma eventual política de bloqueio, é recomendado também a integração com o Anti-Spam da Symantec, SMG (Symantec Messaging Gateway), assim como a integração através do Flex-Response. Deste modo é possível a ativação do modo de quarentena, para que os administradores possam liberar ou excluir mensagem que foram detectadas através do DLP, mantendo assim um maior controle e agilidade no WorkFlow do DLP.
Ponto 2 — Outro monitor recomendado é o Discover, este monitor faz, principalmente, scan de File Server, podendo assim apontar políticas com inteligência para reconhecimento de documentos críticos para o negócio e/ou sigilosos para certas áreas, fazendo com que sejam retirados de certos diretórios e realocados para outro. Assim assegurando que somente os diretórios com acessos permitidos e regulamentados possam ter permissão de leitura e modificação de arquivos específicos.
Esse monitor permite colocar um aviso em forma de .txt no diretório onde o documento que foi realocado estava para que o usuário tenha conhecimento da ação.
Ponto 3 — Para que seja feito testes de políticas e não efetivos bloqueios, é indicado o Detection server Monitor. Esse é o único detection que a Symantec pede para que seja físico, por conta de placas de rede. O detection é ligado diretamente na span port do switch para que monitore e descubra protocolos de tráfego que navegam na rede interna da empresa, sendo assim, possui visão de tudo que for espelhado para ele. Além disso podem fazer testes com qualquer tipo de política que precisem desenvolver e criar maturidade antes de aplicarem para os respectivos monitores.
Conclusão
Não é aconselhável colocar todas as tarefas do Symantec DLP em um único Detection, indica-se que se distribua as tarefas de prevenção para os Detections cada qual com seu canal específico de comunicação.
Este artigo tem como intenção ajudar analistas e consultores da área de segurança da informação, a conseguir promover uma análise do ambiente do produto Symantec DLP.
Leituras recomendadas para mais métodos de proteção e mitigação:
https://support.symantec.com/en_US/article.DOC10941.html
Data Loss Prevention DLP-S500 Hardware Appliance Quick Start Guide
https://www.symantec.com/docs/DOC10613
Symantec Data Loss Prevention Administration Guide
https://www.symantec.com/docs/DOC9261
Symantec Data Loss Prevention Detection Customization Guide
https://www.symantec.com/docs/DOC9356
Symantec Data Loss Prevention Email Quarantine Connect FlexResponse Implementation Guide
https://www.symantec.com/docs/DOC8720
Symantec Data Loss Prevention Endpoint Server Scalability Guide
https://www.symantec.com/docs/DOC8789
Symantec Data Loss Prevention MTA Integration Guide for Network Prevent for Email
https://www.symantec.com/docs/DOC9467
Symantec Data Loss Prevention Release Notes
https://www.symantec.com/docs/DOC10600
Symantec Data Loss Prevention System Maintenance Guide
Symantec Data Loss Prevention System Requirements and Compatibility Guide